- Published on
LangChain
- Authors

- Name
- MissTree
LangChain
特性
- LLM 和提示(Prompt):LangChain 对所有 LLM 大模型进行了 API抽象,统一了大模型访问API,同时提供了 Prompt 提示模板管理机制。
- 链(Chain):Langchain 对一些常见的场景封装了一些现成的模块,例如:基于上下文信息的问答系统,自然语言生成 SQL查询等等,因为实现这些任务的过程就像工作流一样,一步一步的执行,所以叫链(chain)。
- 数据增强生成(RAG):因为大模型(LLM)不了解新的信息,无法回答新的问题,所以我们可以将新的信息导入到 LLM,用于增强 LLM 生成内容的质量,这种模式叫做 RAG 模式(Retrieval AugmentedGeneration)
- Agents:是一种基于大模型(LLM)的应用设计模式,利用LLM 的自然语言理解和推理能力(LLM作为大脑)),根据用户的需求自动调用外部系统、设备共同去完成任务,例如:用户输入“明天请假一天”,大模型(LLM)自动调用请假系统,发起一个请假申请。
- 模型记忆(memory):让大模型(m)记住之前的对话内容,这种能力成为模型记忆(memory)。
核心概念
- LLMS:LangChain 封装的基础模型,模型接收一个文本输入,然后返回一个文本结果。
- Chat Models:聊天模型(或者成为对话模型),与LLMs不同,这些型专为对话场景而设计。型可以接收一组对话消息,然后返回对话消息,类似聊天消息一样。
- 消息(Message):指的是聊天模型(Chat Models)的消息内容,消息类型包括包括 HumanMessage、AIMessage、SystemMessage、FunctionMessage 和ToolMessage 等多种类型的消息。
- chain:链,将多个组件组合在一起,形成一个完整的流程,例如:问答系统,需要将检索到的文档内容,作为输入,传递给 LLM,然后生成答案。
- 提示(prompts):LangChain 封装了一组专门用于提示词(prompts)管理的工具类,方便我们格式化提示词(prompts)内容。
- 输出解析器(Output Parsers):Langchain 接受大模型(llm)返回的文本内容之后,可以使用专门的输出解析器对文本内容进行格式化,例如解析 json、或者将 lm 输出的内容转成 python 对象。
- Retrievers:为方便我们将私有数据导入到大模型(LLM),提高模型回答问题的质量,LangChain 封装了检索框架(Retrievers),方便我们加载文档数据、切割文档数据、存储和检索文档数据。
- 向量存储(Vector stores):为支持私有数据的语义相似搜索,langchain 支持多种向量数据库。
- Agents:智能体 (Agents),通常指的是以大模型(LLM)作为决策引擎,根据用户输入的任务,自动调用外部系统、硬件设备共同完成用户的任务,是一种以大模型(LLM)为核心的应用设计模式。
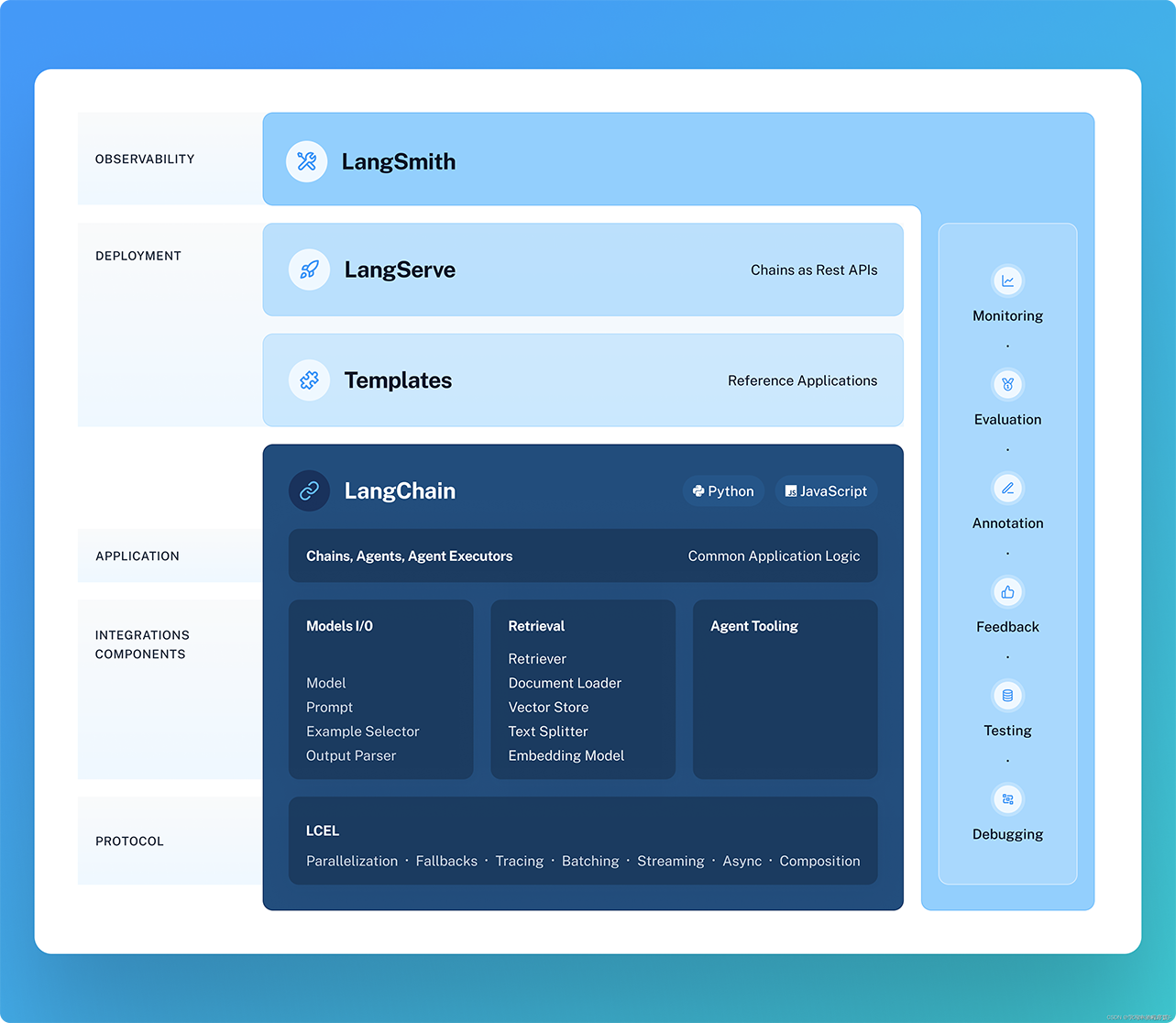
框架组成
- LangChain 库:Python 和JavaScript 库。包含接口和集成多种组件的运行时基础,以及现成的链和代理的实现。
- LangChain 模板:Langchain 官方提供的一些 AI 任务模板
- LangServe:基于 FastAPI 可以将 Langchain 定义的链 (Chain),发布成 REST API
- LangSmith:开发平台,是个云服务,支持Langchain debug、任务监控
HuggingFace
HuggingFace 是一个开源社区,类似GitHub,提供各种预训练模型和工具,用于自然语言处理和机器学习任务。
- HuggingFace Transformers:用于加载和运行各种预训练模型,例如 GPT-3、BERT、T5 等。
- HuggingFace Tokenizers:对文本进行预处理,具体工作包括分词、转换词元 ID 以及处理特殊符号等。它与预训练模型紧密配合,不同的预训练模型通常需要特定的分词器。而且,它支持多种分词方法,如 BPE、WordPiece 等,还能高效处理批量文本。
- HuggingFace Accelerate:用于加速训练和推理,支持分布式训练和推理。轻松扩展训练规模,并且能与现有的训练代码无缝集成。
- HuggingFace Datasets:是加载、处理和缓存各种数据集,像 GLUE、SQuAD 等常见数据集都能处理。它支持多种数据格式,如 CSV、JSON 等,还能高效处理大型数据集,避免占用过多内存。此外,它还提供了评估指标计算功能,方便对模型进行评估。
LangChain检索
Retrieval 给LLM 提供了外部知识,使得 LLM 可以回答一些它没有见过的信息,例如:回答一些历史事件、人物、地理、科学等知识,这些知识是 LLM 在训练时没有见过的,所以 LLM 无法回答这些问题。 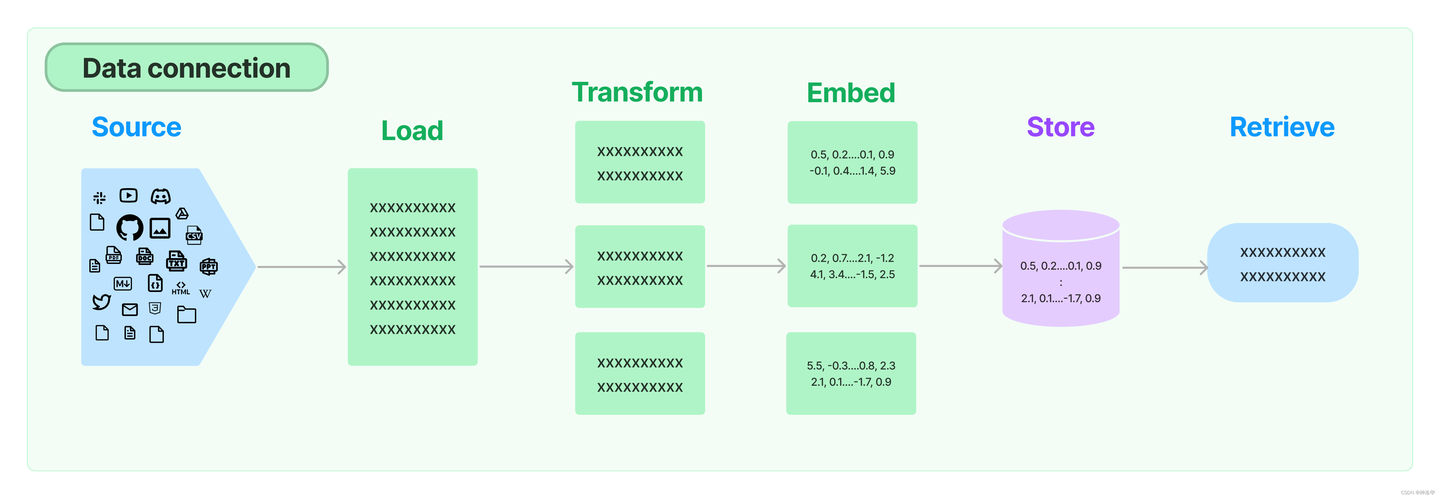
示例
给AI的 system,human,assistant 创建角色,然后让它扮演这个角色,回答问题。
# 引入 langchain 的聊天模板
from langchain_core.prompts import ChatPromptTemplate,SystemMessagePromptTemplate,HumanMessagePromptTemplate
from langchain_openai import OpenAI, ChatOpenAI;
system_template = "你是一位专业智能助理提供信息和帮助,你的名字是{name}"
prompt_template = ChatPromptTemplate.from_messages([
("system", system_template),
("human", "{input}")
])
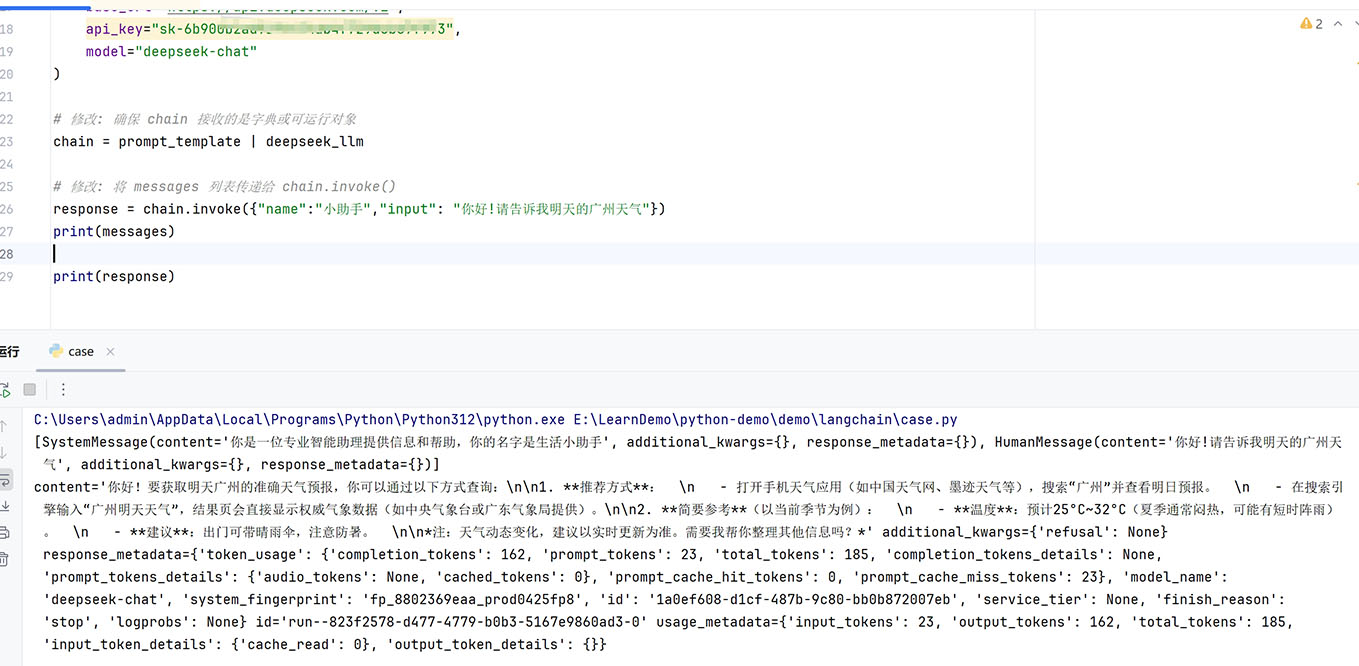
# 修改: 使用 format_messages() 方法生成格式化的消息列表,而不是 format()
messages = prompt_template.format_messages(name="生活小助手", input="你好!请告诉我明天的广州天气")
deepseek_llm = ChatOpenAI(
base_url="https://api.deepseek.com/v1",
api_key="sk-6b900b2ad92f4654axxxxxx",
model="deepseek-chat"
)
# 修改: 确保 chain 接收的是字典或可运行对象
chain = prompt_template | deepseek_llm
# 修改: 将 messages 列表传递给 chain.invoke()
response = chain.invoke({"name":"小助手","input": "你好!请告诉我明天的广州天气"})
print(messages)
print(response)
"""
[SystemMessage(content='你是一位专业智能助理提供信息和帮助,你的名字是生活小助手', additional_kwargs={}, response_metadata={}),
HumanMessage(content='你好!请告诉我明天的广州天气', additional_kwargs={}, response_metadata={})]
content='你好!要获取明天广州的准确天气预报,你可以通过以下方式查询:\n\n1. **推荐方式**: \n - 打开手机天气应用(如中国天气网、墨迹天气等),搜索“广州”并查看明日预报。 \n - 在搜索引擎输入“广州明天天气”,结果页会直接显示权威气象数据(如中央气象台或广东气象局提供)。\n\n2. **简要参考**(以当前季节为例): \n - **温度**:预计25°C~32°C(夏季通常闷热,可能有短时阵雨)。 \n - **建议**:出门可带晴雨伞,注意防暑。 \n\n*注:天气动态变化,建议以实时更新为准。需要我帮你整理其他信息吗?*'
additional_kwargs={'refusal': None} response_metadata={'token_usage': {'completion_tokens': 162, 'prompt_tokens': 23, 'total_tokens': 185, 'completion_tokens_details': None, 'prompt_tokens_details': {'audio_tokens': None, 'cached_tokens': 0}, 'prompt_cache_hit_tokens': 0, 'prompt_cache_miss_tokens': 23}, 'model_name': 'deepseek-chat', 'system_fingerprint': 'fp_8802369eaa_prod0425fp8', 'id': '1a0ef608-d1cf-487b-9c80-bb0b872007eb', 'service_tier': None, 'finish_reason': 'stop', 'logprobs': None} id='run--823f2578-d477-4779-b0b3-5167e9860ad3-0' usage_metadata={'input_tokens': 23, 'output_tokens': 162, 'total_tokens': 185, 'input_token_details': {'cache_read': 0}, 'output_token_details': {}}
"""
# 转成字符串
from langchain_core.output_parsers import StringOutputParser
chain = prompt_template | deepseek_llm | StringOutputParser()
"""
你好!我目前无法实时获取天气信息,但你可以通过以下方式查询广州明天的天气:
1. 使用天气应用(如中国天气网、墨迹天气等)
2. 在搜索引擎输入"广州明天天气"
3. 查看手机自带天气应用
建议查询时注意:
- 更新时间(确保是最新预报)
- 温度范围(广州近期温差可能较大)
- 降水概率(近期可能有阵雨)
需要其他帮助可以随时告诉我~
"""
查看 langchain版本
import langchain
import langchain_core
print(langchain.__version__)
print(langchain_core.__version__)
langchain 提示词模板
提示词模板分为两种:ChatPromptTemplate(聊天对话模式) 和 PromptTemplate(字符串简单提示词)
from langchain_core.prompts import ChatPromptTemplate, HumanMessage, MessagePlacholder
system_template = "你是一位专业智能助理提供信息和帮助,你的名字是{name}"
prompt_template = ChatPromptTemplate.from_messages([
("system", system_template),
("human", "{input}").
# 传入一组预先输入的消息
MessagePlacholder('msg')
])
"""
prompt_template = PromptTemplate.from_messages(
"给我讲一个关于{content}的{adjective}笑话。"
)
"""
...
response = chain.invoke({"msg":[HumanMessage(content="你好!请告诉我明天的广州天气"),HumanMessage(content="上面的问题回答不完整,请继续回答")]})
ChatPromptTemplate 聊天模板可以通过 from_messages() 方法创建,该方法接受一个消息列表,每个消息都有角色和内容。可以作为一个微调器,将消息列表转换为格式化的消息列表,以便传递给 LLM。
from langchain_core.prompts import ChatPromptTemplate, HumanMessage, MessagePlacholder
system_template = "你是一位专业智能助理提供信息和帮助,你的名字是{name}"
prompt_template = ChatPromptTemplate.from_messages([
("system", system_template),
("human", "{input}").
# 传入一组预先输入的消息
MessagePlacholder('msg')
])
...
提示词追加
from langchain.prompts import PromptTemplate
from langchain.prompts.few_shot import FewShotPromptTemplate
example=[
{
"question": "建党节是哪一天",
"answer": "7月1日"
},
{
"question": "建军节是哪一天",
"answer": "8月1日"
},
]
example_prompt = PromptTemplate(input_variables=["question", "answer"], template="问题: {question}\\n 答案:{answer}")
# examples 接收示例数组参数,example_prompt 接收示例模板,suffix 接收后缀内容,input_variables 接收输入变量
# input_variables 用于定义suffix 模板中替换为实际值。
few_shot_prompt = FewShotPromptTemplate(
examples=example,
example_prompt=example_prompt, # 修正拼写错误
suffix="问题: {input}", # 确保suffix包含input_variables中定义的变量
input_variables=["input"]
)
print(few_shot_prompt.format(input="建党节是哪一天"))
print(example_prompt.format(**example[0]))
示例选择器
在嵌入模型计算输入和小样本示例之间的相似性,然后使用向量数据库执行相似搜索,获取跟输入相似的示例
from langchain.prompts.example_selector import SemanticSimilarityExampleSelector
...
selector = SemanticSimilarityExampleSelector(
llm=deepseek_llm,
example_prompt=example_prompt,
k=2, # 选择2个最相似的示例
max_examples=10, # 最多考虑10个示例
max_tokens=100, # 限制输入长度
temperature=0.1, # 控制随机性
top_k=5, # 选择最相似的5个示例
)
...
from langchain.prompts.few_shot import FewShotPromptTemplate
from langchain.prompts.prompt import PromptTemplate
from langchain.prompts.example_selector import LengthBasedExampleSelector
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
# 定义示例集,包含多个问题及对应答案的详细推理过程
examples = [
{
"question": "《哈利·波特》和《指环王》的原著作者都是女性吗?",
"answer":
"""
这里需要跟进问题吗:是的。
跟进:《哈利·波特》的原著作者是谁?
中间答案:《哈利·波特》的原著作者是J.K.罗琳(J.K. Rowling)。
跟进:J.K.罗琳是男性还是女性?
中间答案:女性。
跟进:《指环王》的原著作者是谁?
中间答案:《指环王》的原著作者是J.R.R.托尔金(J.R.R. Tolkien)。
跟进:J.R.R.托尔金是男性还是女性?
中间答案:男性。
所以最终答案是:不是
"""
},
...
]
# 定义示例提示词模板,指定输入变量和模板格式
example_prompt = PromptTemplate(input_variables=["question", "answer"], template="问题:{question}\n{answer}")
# 创建基于长度的示例选择器,根据输入长度选择合适数量的示例
example_selector = LengthBasedExampleSelector(
examples=examples,
example_prompt=example_prompt,
max_length=200 # 可根据实际情况调整最大长度
)
# 创建少样本提示模板,结合示例选择器、示例提示词模板及后缀等信息
prompt = FewShotPromptTemplate(
example_selector=example_selector,
example_prompt=example_prompt,
suffix="问题:{input}",
input_variables=["input"]
)
# 初始化 ChatOpenAI 语言模型
chat_model = ChatOpenAI(
base_url="https://api.deepseek.com/v1",
api_key="sk-6b9xxxxxxxxxxxxxxxxxxxxxxxxxxx",
model="deepseek-chat"
)
# 该解析器用于将模型的输出结果解析为字符串类型
output_parser = StrOutputParser()
# 使用管道操作符|将提示模板、聊天模型和输出解析器连接起来,形成一个处理链
chain = prompt | chat_model | output_parser
# 用户新的问题
new_question = "牛顿和爱因斯坦谁提出重要理论的时间更早?"
# 与大模型交互,获取回答
response = chain.invoke({"input": new_question})
print(f"问题: {new_question}")
print(f"回答: {response}")
提示词模板
from langchain.prompts import PromptTemplate
from langchain.prompts.few_shot import FewShotPromptTemplate
example=[
{
"question": "建党节是哪一天",
#### 保护 API 密钥
```python
import os
from langchain_openai import ChatOpenAI
deepseek_llm = ChatOpenAI(
base_url="https://api.deepseek.com/v1",
api_key=os.getenv("DEEPSEEK_API_KEY"), # 从环境变量读取
model="deepseek-chat"
)
LangChain 工作流编排
LCEL介绍
LCEL(LangChain Expression Language)是一种强大的工作流编排工具,可以从基本组件构建复杂任务链条(chain),并支持诸如流式处理、并行处理和日志记录等开箱即用的功能。
- 优化并行的执行:支持同步和异步执行
- 重试和回退:任何部分的配置重试和回退,可以获得额外的可靠性二无需任何延迟成本。
- 流式处理:支持流式处理,可以实时获取结果,无需等待整个链条执行完成。
- 访问中间结果: 对于更复杂的链,访问中间步骤的结果通常非常有用,即使在生成最终输出之前。这可以用于让最终用户知道正在发生的事情,甚至只是用于调试您的链。您可以流式传输中间结果,并且在每个LangServe 服务器上都可以使用。
- 输入和输出模式: 输入和输出模式为每个 LCEL 链提供了从链的结构推断出的 Pydantic 和JSONSchema 模式。这可用于验证输入和输出,并且是 LangServe 的一个组成部分。
Runable interface
标准接口包含:
- stream: 返回响应的数据块
- invoke: 对输入调用链
- batch: 对输入列表调用链
- astream:异步返回响应的数据块
- ainvoke:异步对输入调用链
- abatch:异步对输入列表调用链
- astream_log:异步返回中间步骤,以及最终响应
- astream events:beta 流式传输链中发生的事件(在 langchain-core 0.1.14 中引入)
from langchain_openai import ChatOpenAI
model = ChatOpenAI(
base_url="https://api.deepseek.com/v1",
api_key="sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx",
model="deepseek-chat"
)
chunk = []
for _ in model.stream('广东夏天是怎么样的'):
chunk.append(_)
#打印出来就有现在chatai的输出感觉
print(_.content,end='|',flush=True)
print(chunk)
# 异步模式
import asyncio # 异步调用
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
model = ChatOpenAI(
base_url="https://api.deepseek.com/v1",
api_key="sk-xxxxxxxxxxxxxxxxxxx",
model="deepseek-chat"
)
prompt = ChatPromptTemplate.from_template("请给我讲一个{text}故事")
chain = prompt | model | StrOutputParser()
chunks = []
async def chat_await():
async for i in chain.astream({"text":'广东夏天'}):
chunks.append(i)
print(i,end='|',flush=True)
asyncio.run(chat_await())
流式调用可以优化用户的体验,因为它允许用户在等待结果时看到部分输出,而不是等待整个链条执行完成。这对于长时间运行的任务或需要实时反馈的任务非常有用。
Stream events(事件流)
- on_chat_model_start: 在聊天模型开始处理请求时触发
- on_chat_model_end: 在聊天模型完成处理请求时触发
- on_chat_model_chunk: 在聊天模型生成新的输出块时触发
- on_chat_model_error: 在聊天模型处理请求时发生错误时触发
- on_chat_model_stream: 在聊天模型流式处理请求时触发
- on_llm_start: 在 LLM 开始处理请求时触发
- on_llm_end: 在 LLM 完成处理请求时触发
- on_llm_chunk: 在 LLM 生成新的输出块时触发
- on_llm_error: 在 LLM 处理请求时发生错误时触发
- on_chain_start: 在链条开始处理请求时触发
- on_chain_end: 在链条完成处理请求时触发
- on_tool_start: 在工具开始处理请求时触发
- on_tool_end: 在工具完成处理请求时触发
- on_prompt_start: 在提示开始处理请求时触发
- on_prompt_end: 在提示完成处理请求时触发
- on_retrieval_start: 在检索开始处理请求时触发
- on_retrieval_end: 在检索完成处理请求时触发
- on_output_parser_start: 在输出解析器开始处理请求时触发
- on_output_parser_end: 在输出解析器完成处理请求时触发
- on_input_parser_start: 在输入解析器开始处理请求时触发
import asyncio # 异步调用
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
model = ChatOpenAI(
base_url="https://api.deepseek.com/v1",
api_key="sk-6b90xxxxxxxxxxxxxxxxxxx",
model="deepseek-chat"
)
prompt = ChatPromptTemplate.from_template("请给我讲一个{text}故事")
events = []
async def chat_await():
async for n in model.astream_events("请给我讲一个50字内的笑话故事",version="v2"):
events.append(n)
print(events)
asyncio.run(chat_await())
# 并发执行任务
asyncio.gather(chat_await(),chat_await())
LangChain 模型
Model I/O 是LangChain-community 的核心组件之一,它负责加载和运行各种大模型,包括 LLM 和 Chat Model。 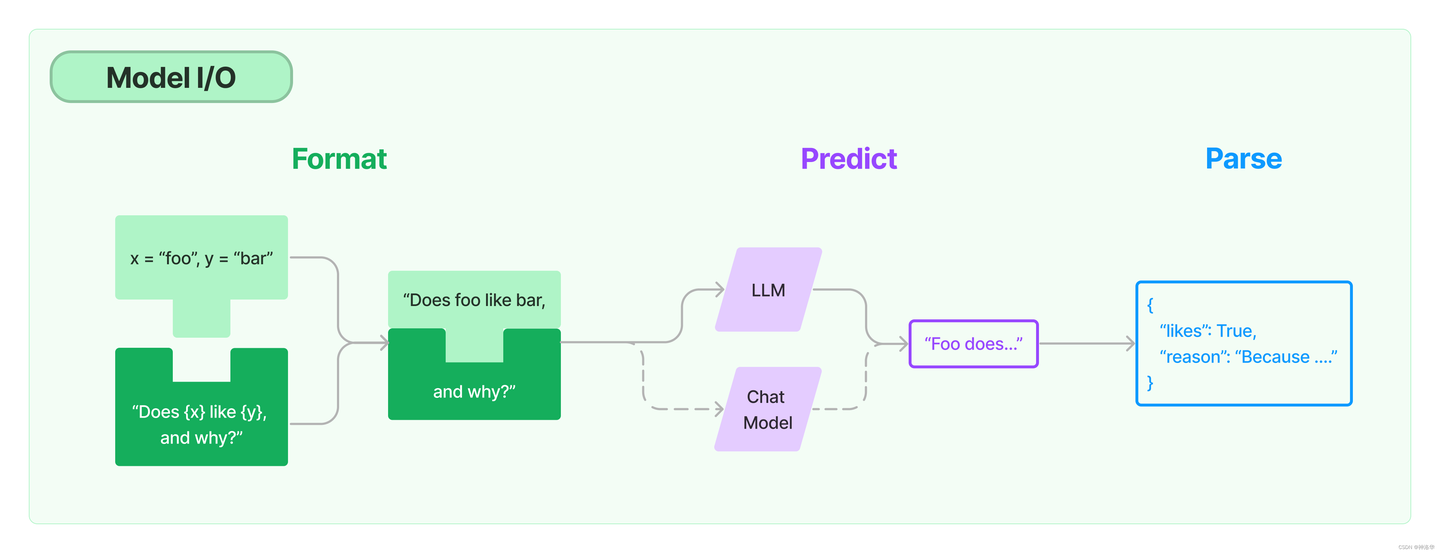
LangChain 服务部署与链路监控
LangServe 服务部署
LangServee帮助开发者将 Langchain 可运行和链部署为 REST API。该库集成了 FastAPI 并使用 pydantic 进行数据验证。
Pydantic 是Python中使用广泛的数据验证库。它利用声明式的方式定义数据模型和Python 类型提示的强大功能来执行数据验证和序列化,使您的代 码更可靠、更可读、更简洁且更易于调试。它还可以从模型生成 JSON 架构,提供了自动生成文档等功能,从而轻松与其他工具集成此外,它提供了一个客户端,可用于调用部署在服务器上的可运行对象。JavaScript 客户端可在LangChain.js 中找到。
安装
pip install --upgrade "langserve[all]"
# 客户端
pip install "langserve[client]"
# 服务端
pip install "langserve[server]"
LangChain-Cli
LangChain-Cli 是一个命令行工具,用于管理和运行 LangChain 链。
安装
pip install -U langchain-cli
使用
# 初始化 LangChain 配置文件
Usage: langchain [OPTIONS] COMMAND [ARGS]...
╭─ Options ─────────────────────────────────────────╮
│ --version -v Print the current CLI version. │
│ --help Show this message and exit. │
╰───────────────────────────────────────────────╯
╭─ Commands ─────────────────────────────────────────╮
│ migrate Migrate langchain to the most recent version. │
│ serve Start the LangServe app, whether it's a template or an app. │
│ template Develop installable templates. │
│ app Manage LangChain apps │
│ integration Develop integration packages for LangChain. │
╰────────────────────────────────────────────────╯
# langserve 为项目名称
langchain app new langserve
# 按顺序安装模块
# 1.安装 pipx (https://pipx.pypa.io/stable/installation/) 成功后在控制台执行 pipx 会出现对应的命令
pip install pipx
# 2.配置环境变量 配置完成后关闭 pycharm 重启
pipx ensurepath
# 3.安装poetry 便于安装项目依赖,参考:https://python-poetry.org/docs/
pipx install poetry
# 4.切入项目文件夹安装 langchain-openai库,例如:poetry add[package-name]
poetry add langchain
poetry add langchaih-openai
poetry install # 安装依赖
# 报错解决
# Command '['C:\\Users\\admin\\AppData\\Local\\Microsoft\\WindowsApps\\python.EXE', '-EsSc', 'import sys; print(sys.executable)']'
# returned non-zero exit status 9009.
# 问题原因:通常发生在 Windows 系统中,当 Poetry 无法正确识别 Python 解释器路径时。错误代码 9009 表示系统找不到指定的文件或命令。
# 1.在环境变量中添加python.exe的路径,并且将位置移到最前面
# poetry add langchain 报错:Because no versions of langchain match >0.3.25,<0.4.0 and langchain (0.3.25) depends on pydantic (>=2.7.4,<3.0.0), langchain (>=0.3.25,<0.4.0) requires pydantic (>=2.7.4,<3.0.0).
# So, because langserve-tool depends on both pydantic (<2) and langchain (^0.3.25), version solving failed.
# 修改pyproject.toml 属性 pydantic = "<2" 变成pydantic = ">2"
项目 /app/server.py 调整对应代码
from fastapi import FastAPI
from fastapi.responses import RedirectResponse
from langserve import add_routes
from langchain_openai import ChatOpenAI
# 创建 FastAPI 应用和对应api文档描述
app = FastAPI(
title="LangServe Example",
description="An example LangServe app",
version="0.0.1",
)
@app.get("/")
async def redirect_root_to_docs():
return RedirectResponse("/docs")
# Edit this to add the chain you want to add
add_routes(
app,
ChatOpenAI(
base_url="https://api.deepseek.com/v1",
api_key="sk-6bxxxxxxxxxxxxxxx",
model="deepseek-chat"
),
path="/openai",
)
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
启动项目 poetry run langchain serve --port=8000
添加API路由
from langchain.schema.runnable import RunnableMap
from langchain_core.prompts import ChatPromptTemplate
from langserve import RemoteRunnable
# # 连接到远程服务
# openai = RemoteRunnable("http://localhost:8000/openai")
# prompt = ChatPromptTemplate.from_messages([
# ("system","你是一个写冷笑话的AI助手"),
# ("user","一个关于{text}的故事")
# ])
#
# chain = prompt | RunnableMap({
# "model": openai
# })
# response = chain.invoke([{"text":"猫"}])
# print(response)
#
# joke_chain = RemoteRunnable("http://localhost:8000/joke")
# # 调用方式2 - 直接调用joke链
# response = joke_chain.invoke({"text": "猫"})
# print(response)
# 连接到远程服务
openai = RemoteRunnable("http://localhost:8000/openai")
joke_chain = RemoteRunnable("http://localhost:8000/joke")
# 方式1 - 直接调用openai链
prompt = ChatPromptTemplate.from_messages([
("system","你是一个写冷笑话的AI助手"),
("user","一个关于{type}的故事")
])
chain = prompt | RunnableMap({
"model": openai
})
response = chain.invoke({"type": "狗"})
print("OpenAI响应:", response)
# 方式2 - 调用joke链
response = joke_chain.invoke({"text": "猫"})
print("笑话响应:", response)
langsmith 服务监控
与构建任何类型的软件一样,使用LLM构建时,总会有调试的需求。型调用可能会失败,型输出可能格式错误,或者可能存在一些嵌套的模型调用,不清楚在哪一步出现了错误的输出
#windows导入环境变量
#配置LangSmith 监控开关,true开启,false关闭
setX LANGCHAIN TRACING V2 "true"
#配置 Langsmith api key
setx LANGCHAIN API KEY。
#配 taily api key
setX TAVILY API KEY
LangSmith官网:https://smith.angchain.com/ tavily官网:https://tavily.com/
from langchain_openai import ChatOpenAI
from langchain.agents import AgentExecutor, create_tool_calling_agent
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain_core.prompts import ChatPromptTemplate
llm = ChatOpenAI(model="gpt-4o")
# 大模型具有时间限制,需要调用检索获取最新数据
tools =[TavilySearchResults(max_resuts=1)]
prompt = ChatPromptTemplate.from_messages([
()"system","你是一位得力的助手。")
("placeholderI,"{chat_history}"),
("human","{input}"),
("placeholder","{agent_scratchpad}")
])
# 构建工具代理
agent = create_tool_calling_agent(llm, tools, prompt)
#通过传入代所和工具来创建代理执行器
agent_executor = AgentExecutor(agent=agent, tools=tools)
response = agent_executor.invoke({"input":“谁指导电影《功夫》,他多少岁了?"})
print(response)
verbose
详细日志
from langchain_openai import ChatOpenAI
from langchain.agents import AgentExecutor, create_tool_calling_agent
#pip install U langchain-comunity tavily-pythonNsetx TAVILY_API KEY "your-api-key"
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain_core.prompts import ChatPromptTemplate
from langchain.globals import set_verbose
llm=ChatOpenAI(model="gpt-4o")
tools =[TavilySearchResults(max_results=1)]
prompt =ChatPromptTemplate.from_messages([
("system","你是一位得力的助手。")
("placeholder","{chat_history}"),
("human","{input}"),
("placeholder","{agent_scratchpad}"),
])
# 构建工具代理
agent = create_tool_calling_agent(llm, tools, prompt)
# 打印详细日志
set_verbose(True)
#通过传入代所和工具来创建代理执行器
agent_executor = AgentExecutor(agent=agent, tools=tools)
response = agent_executor.invoke({"input":“谁指导电影《功夫》,他多少岁了?"})
print(response)
debug
调试日志打印 设置全局的 debug 标志将导致所有具有回调支持的 LangChain 组件(链、模型、代理、工具、检索器)打印它们接收的输入和生成的输出。这是最详细的设置,将完全记录原始输入和输出。
from langchain_openai import ChatOpenAI
from langchain.agents import AgentExecutor, create_tool_calling_agent
#pip install U langchain-comunity tavily-pythonNsetx TAVILY_API KEY "your-api-key"
from langchain_community.tools.tavily_search import TavilySearchResults
from langchain_core.prompts import ChatPromptTemplate
from langchain.globals import set_debug
llm=ChatOpenAI(model="gpt-4o")
tools =[TavilySearchResults(max_results=1)]
prompt =ChatPromptTemplate.from_messages([
("system","你是一位得力的助手。")
("placeholder","{chat_history}"),
("human","{input}"),
("placeholder","{agent_scratchpad}"),
])
# 构建工具代理
agent = create_tool_calling_agent(llm, tools, prompt)
# 打印详细日志
set_debug(True)
#通过传入代所和工具来创建代理执行器
agent_executor = AgentExecutor(agent=agent, tools=tools)
response = agent_executor.invoke({"input":“谁指导电影《功夫》,他多少岁了?"})
print(response)
三者区别
| 分类 | verbose | debug | langsmith |
|---|---|---|---|
| 免费 | ✓ | ✓ | ✓ |
| 用户界面 | × | × | ✓ |
| 持久化 | × | × | ✓ |
| 查看所有事件 | × | ✓ | ✓ |
| 查看"重要"事件 | ✓ | × | ✓ |
| 本地运行 | ✓ | ✓ | × |
RAG和微调
| 比较 | RAG | 微调 |
|---|---|---|
| 知识更新 | 直接更新检索知识库,无需重新训练。信息更新成本低,适合动态变化的数据。 | 通常需要重新训练来保持知识和数据的更新。更新成本高,适合静态数据。 |
| 外部知识 | 擅长利用外部资源,特别适合处理文档或其他结构化/非结构化数据库 | 将外部知识学习到 LLM 内部 |
| 数据处理 | 对数据的处理和操作要求极低。 | 依赖于构建高质量的数据集,有限的数据集可能无法显著提高性能。 |
| 模型定制 | 侧重于信息检索和融合外部知识,但可能无法充分定制模型行为或写作风格。 | 可以根据特定风格或术语调整 LLM 行为、写作风格或特定领域知识。 |
| 可解释性 | 可以追溯到具体的数据来源,有较好的可解释性和可追踪性。 | 黑盒子,可解释性相对较低。 |
| 计算资源 | 需要额外的资源来支持检索机制和数据库的维护 | 依赖高质量的训练数据集和微调目标,对计算资源的要求较高 |
| 推理延迟 | 增加了检索步骤的耗时 | 单纯 LLM 生成的耗时 |
| 降低幻觉 | 通过检索到的真实信息生成回答,降低了产生幻觉的概率 | 模型学习特定领域的数据有助于减少幻觉,但面对未见过的输入时仍可能出现幻觉。 |
| 伦理隐私 | 检索和使用外部数据可能引发伦理和隐私方面的问题 | 训练数据中的敏感信息需要妥善处理,以防泄露。 |
RAG
chat聊天插入
在之前的聊天结果查询输入结果
from langchain.prompts import PromptTemplate
from langchain.prompts.few_shot import FewShotPromptTemplate
example=[
{
"question": "建党节是哪一天",
"answer": "7月1日"
},
{
"question": "建军节是哪一天",
"answer": "8月1日"
},
]
example_prompt = PromptTemplate(input_variables=["question", "answer"], template="问题: {question}\\n{answer}")
# examples 接收示例数组参数,example_prompt 接收示例模板,suffix 接收后缀内容,input_variables 接收输入变量
# input_variables 用于定义suffix 模板中替换为实际值。
few_shot_prompt = FewShotPromptTemplate(
examples=example,
example_prompt=example_prompt, # 修正拼写错误
suffix="问题: {input}", # 确保suffix包含input_variables中定义的变量
input_variables=["input"]
)
print(few_shot_prompt.format(input="建党节是哪一天"))