
python
安装
python应用场景
- 网络爬虫
- 数据分析
- 人工智能 (python只占 5%~10%,其他都是算法)
- 自动化脚本 (自动化测试、自动化运维、自动化部署、自动化任务使用第三方库Selenium)
- 网站开发
- 游戏开发
官网下载,也可以选择指定版本下载 下载完成后,双击安装,在开始安装界面上Use admin privileges when installing py.exe和Add python.exe to PATH勾选上,其余默认安装即可。 安装完成后,打开命令行,输入python,如果能看到版本信息,说明安装成功。 
pycharm
pycharm官网
PyCharm是一款Python的集成开发环境在Windows、Mac OS和Linux操作系统中都可以使用带有一整会可以帮助用户在使用Python语言开发时提T具高效率的工具。分为社区版和专业版,社区版免费,专业版需要付费。
pip安装源
pip是Python的包管理工具,用于安装、升级和管理Python包。 pip的安装源可以通过修改配置文件来实现。 在Windows系统中,可以通过以下步骤修改pip的安装源: 打开命令行工具,输入以下命令:
# 临时设置
pip install -i https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple some-package
# 永久设置
pip config set global.index-url https://mirrors.tuna.tsinghua.edu.cn/pypi/web/simple
python基础语法
变量
变量是用于存储数据的容器,在Python中,变量不需要声明,直接赋值即可。 变量名可以包含字母、数字和下划线,但是不能以数字开头,不要用中文、关键字(true、break、while、async)。
import keyword
# 查询关键字
print(keyword.kwlist)
print(len(keyword.kwlist))
# 变量赋值的时候赋值的堆内存地址
no=number=8
# 两者的地址是一样的
print(id(no))
print(id(number))
name = "John"
age = 30
is_student = True
# 字符串
message = "Hello, World!"
# 操作方式 + :只能两个字符串相加 *:只能一个字符串和一个数字相乘,表示字符串重复的次数
message = "Hello, " + name + "!"
message = "Hello, " * 3
# 提示语
a = input("请输入一个数字:") # 执行的适合提示输入的内容是字符串类型
type(a) # 查看变量类型 ==> str
b = input("请输入一个数字:") # 执行的适合提示输入的内容是字符串类型
print("两个数字的和为:", int(a) + int(b))
字符串
| 转义字符 | 描述说明 |
|---|---|
| \n | 换行符 |
| \t | 水平制表位,用于横向跳到下一个制表位 |
| \" | 双引号 |
| \' | 单引号 |
| \\ | 一个反斜杠 |
原字符:使转义字符失效的字符,r或R开头的字符串,其中的所有字符都不转义。
name = input('请输入名称')
age = int(input('请输入年龄'))
address = input('请输入地址')
s="我叫%s,今年%d,我住在%s"%(name,age,address)
s0="我叫%s"%name # 只有一个变量可以不用()
s1="我叫{},今年{},我住在{}".format(name,age,address)
# 3.5版本支持的写法
s2=f"我叫{name},今年{age},我住在{address}"
print(s)
print(s1)
print(s2)
# 索引和切片
a='hello World'
a[-3:-1] # 还是从左往右切
a[-3:-1] # 没有结果
a[::-1] # 表示从右往左
# a[start:end:step] 从start开始切,end结束, step个间隔
a[0:5:2] # 从0开始切,5结束,2个间隔
# 多行字符串
a=''' 第一行
第二行
hello World
hello World
'''
# 字符串的方法
a='hello World'
a.capitalize() # 首字母大写
a.upper() # 全部大写
print(a.lower())
print(a.upper())
b='hel lo '
# 去除字符串两边空格
print(b.strip())
# 字符串替换
print(b.replace(' ','x'))
# 字符串切割
print(b.split(' l'))
print(b.find('ll')) # 没有就是 -1
print(b.startswith('he')) # 是否以什么开头
print(b.index('ll')) # 没有就会报错
print(b.count('o')) # o 出现的次数
print('x' in b) # 返回 bool
# 判断字符串是否是数字
a='123' b='123a' c=['123.123', '123.123a','123a123','123a123.123']
print(a.isdigit()) # True 是否是数字
print(a.isalpha()) # False 是否是字母
print(a.isalnum()) # True 是否是数字和字母
print(a.isspace()) # False 是否是空格
print(a.istitle()) # False 是否是标题
print(a.isdecimal()) # True 是否是十进制
print(a.isnumeric()) # True 是否是数字
print(a.isprintable()) # True 是否是可打印的
print(a.isidentifier()) # True 是否是标识符
print(a.isascii()) # True 是否是ascii码
print(a.islower()) # True 是否是小写
print(a.isupper()) # False 是否是大写
print(a.zfill(5)) # 用0填充到5位
print(a.ljust(5)) # 左对齐
print(a.rjust(5)) # 右对齐
print(a.center(5)) # 居中
print(a.lstrip()) # 去除左边的空格
print(a.join(b)) # 将b中的元素用a连接起来
print(a.join(c)) # 将c中的元素用a连接起来
数字
a=10
b=20
print(a+b) # 30
print(a-b) # -10
print(a*b) # 200
print(a/b) # 0.5
print(a//b) # 0 取整
print(a%b) # 10 余
# 幂运算
print(a**b) # 10的20次方
print(a**0.5) # 开根号
列表
列表是一种有序的集合,可以包含任意类型的数据。python的内置函数是list()。
lt = []
# 尾部添加
lt.append('张三')
# 插入
lt.insert(0,'赵敏')
# 尾部批量添加
lt.extend(['武则天','金毛狮王'])
print(lt)
lt[2]='修改'
print(lt)
lt.remove('张三') # 删除某个元素
lt.pop(1) # 删除索引下的元素
print(lt)
lt.clear() # 清空列表
lt.copy() # 复制列表
lt.index('赵敏') # 查找元素的索引
lt.count('赵敏') # 查找元素的个数
lt.reverse() # 反转列表
b=[2,33,44,11,8,99]
b.sort() # 升序排序
print(b)
b.sort(reverse=True) # 降序排序
print(b)
l= list('helloworld')
print(l)
# 创建列表
a = [for i in range(1, 10)] # 从1到9
b = [random.randint(1, 100) for i in range(10)] # 随机生成10个1到100的数字
c = [i for i in range(1, 10) if i % 2 == 0] # 从1到9,只保留偶数
d = [i for i in range(1, 10) if i % 2 != 0] # 从1到9,只保留奇数
元组
元组是一种有序的集合,可以包含任意类型的数据。
- 固定了元素后,外界不能修改
- 元组的元素不能修改(可以理解为内存地址不能修改),但是可以包含可变对象,比如列表。
- 元组可以作为字典的键,列表不能作为字典的键。
- 元组只有一个元素时,需要在元素后面加上逗号,否则会被认为是变量。 m=(1,)
t=tuple(2,4,6,8,10)
h=(i for i in range(1,10)) # 生成器对象
c=(1,3,6,8,['哈哈','呵呵'])
c[1]=69 # 报错 TypeError: 'tuple' object does not support item assignment
c[4][0]='嘻嘻' # 可以修改
# 元组的遍历
for item in t:
print(item)
for i,el in enumerate(t):
print(i,el)
| 元组 | 列表 |
|---|---|
| 不可变序列 | 可变序列 |
| 无法实现添加、删除和修改元素等操作 | apend()、insert()、remove()、pop()等方法实现添加和子重除列表元素 |
| 支持切片访问元素,不支持修改操作 | 持切片访问和修改列表中的元素 |
| 访问和处理速度快 | 访问和处理速度慢 |
| 可以作为字典的键 | 不可以作为字典的键 |
字典
字典是一种无序的集合,可以包含任意类型的数据,列表不能作为字典的键。类似于java或者JavaScript中的map对象
d={'name':'张三','age':18,'sex':'男'}
# 字典生成式
d={ key:value for item in range }
d={key:value for key,value in zip(lst1lst2)}
d={i:i**2 for i in range(1,10)} # 生成1到9的平方
d={i:i**2 for i in range(1,10) if i%2==0} # 生成1到9的平方,只保留偶数
list(d.keys()) # 取出所有的键
list(d.values()) # 取出所有的值
list(d.items()) # 取出所有的键值对
d.get('name') # 取出某个键的值
d.get('name','李四') # 取出某个键的值,如果不存在就返回默认值
d.pop('name') # 删除某个键的值
d.popitem() # 删除最后一个键值对
d.clear() # 清空字典
d.copy() # 复制字典
d.update({'name':'李四'}) # 更新字典
d.update({'name':'李四','age':19}) # 更新字典
# zip函数
a = [1, 2, 3]
b = ['cat', 'dog', '666']
c = zip(a, b) # 合并两个列表
print(c) # <zip object at 0x000001D199130A00>
m=dict(c) # 转换为字典
print(m) # {1: 'cat', 2: 'dog', 3: '666'}
print(dict(zip(['name', 'age', 'sex'], ['张三', 18, '男']))) # {'name': '张三', 'age': 18, 'sex': '男'}
集合
集合是一种无序不重复的集合,可以包含任意不可变类型的数据。
s={1,2,3,4,5,6,7,8,9}
s1=set('hello world') # 去重 {'h', 'w', 'l', 'd', 'e', 'o', 'r'}
s.add(10) # 添加元素
s.remove(10) # 删除元素
s.pop() # 删除第一个元素
s.clear() # 清空集合
s.copy() # 复制集合
s.update({10,11,12},{13,14,15}) # 更新集合
s=set()
s1={}
print(s,type(s)) # set() <class 'set'>
print(s1,type(s1)) # {} <class 'dict'>
| 数据类型 | 序列类型 | 元素是否可重复 | 是否有序 | 定义符号 |
|---|---|---|---|---|
| 列表list | 可变序列 | 重复 | 有序 | [] |
| 元组tuple | 不可变序列 | 重复 | 有序 | () |
| 字典dict | 可变序列 | key不重复 value可以重复 | 无序 | {key:value} |
| 集合 | 可变序列 | 不可重复 | 无序 | |
常量
常量是指在程序运行期间其值不能被改变的变量。在Python中,常量通常用大写字母表示。
PI = 3.14159265359
MAX_VALUE = 1000
# 注意:Python中没有真正的常量,但是可以通过约定俗成的方式来表示常量。
PI = 3
print函数
print函数用于输出信息到控制台,是python的内置函数。
print(ord('北')) # 输出编码值 21271
print(chr(21271)) # 输出字符 北
print("Hello, World!")
# 将文字输出到文件中
fp = open("test.txt", "w") # 打开文件,w表示写入模式,如果文件不存在则创建,如果文件存在则覆盖
print("Hello, World!",file = fp) # 输出内容到文件
fp.close()
# 方式 二
fp = open("test.txt", "w") # 打开文件,w表示写入模式,如果文件不存在则创建,如果文件存在则覆盖
fp.write("Hello, World!") # 写入文件
fp.close() # 关闭文件
文件操作
open函数的参数
- file: 必需,文件路径和名称。
- mode: 可选,文件打开模式,默认为只读模式。
- r: 只读模式,文件必须存在,否则会报错。
- w: 写入模式,文件不存在则创建,文件存在则覆盖,w 模式会清空文件内容。
- a: 追加模式,文件不存在则创建,文件存在则在文件末尾追加内容。
- b: bytes 二进制模式,用于读写二进制文件。
- encoding: 可选,默认 utf-8 。
# 打开文件
fp = open("test.txt", mode="r",encoding='utf-8') # 打开文件,r表示读取模式,如果文件不存在则报错
# 若是在官网下载的中文版本的 pycharm ,则需要指定编码格式,否则会出现乱码,因为默认是gbk编码格式
# 读取文件
fp.read() # 读取文件的内容
fp.seek(3) # 将文件指针移动到文件第一个字后, 一个文字占3个字节 utf-8
fp.readline() # 读取文件的一行
fp.readlines() # 读取文件的所有行
# 写入文件
fp.write("Hello, World!")
# 关闭文件
fp.close()
# 方式 二 不需要关闭文件 使用 with 语句,上下文,会自动关闭文件
with open("test.txt", mode="r",encoding='utf-8') as fp:
fp.read() # 读取文件的内容
# 读取图片
with open("test.jpeg", mode="rb") as fp: # 读取图片,rb表示二进制模式
fp.read() # 读取文件的内容
# 文件复制 分行展示加 \ 表示连接下一行
with open("test.txt", mode="r",encoding='utf-8') as fp,\
open("test2.txt", mode="w",encoding='utf-8') as fp2:
for line in fp:
fp2.write(line)
with open("test.jpeg", mode="rb") as fp,\
open("test2.jpeg", mode="wb") as fp2:
for line in fp:
fp2.write(line)
文件修改
import os # 导入os模块
import time # 导入time模块
# 删除文件
os.remove("test.txt")
# 休眠3秒
time.sleep(3)
# 修改文件名称
os.rename("test6.txt", "test9.txt")
条件语句
# 条件语句
money = int (print("请输入你的金额:")) # 输入的内容是字符串类型,需要转换为数字类型
if money > 200:
if money > 5000:
print("冲个卡")
else:
print("洗个脚")
else:
print("回家睡觉")
if money > 200:
print("洗个脚")
elif money > 5000:
print("冲个卡")
else:
print("回家睡觉")
# pass语句
if money > 200:
pass # 占位符,用于占位,不执行任何操作
循环语句
for i in range(1, 10): # 从1到9
print(i)
else: # 循环结束后执行
print("循环结束")
for i in range(1, 10,2): # 循环5此, 从1到9 间隔是2
print(i)
q='这是一个字符串循环'
for i in q: # 从1到9
print(i)
while i<100: # 死循环
money = int (print("请输入你的金额:")) # 输入的内容是字符串类型,需要转换为数字类型
i-=1
else: # 循环结束后执行
print("循环结束")
score = ini(input("请输入你的成绩:")) # 输入的内容是字符串类型,需要转换为数字类型
# match 是 Python 3.10 新增的关键字,用于匹配多个值。
match score: # 匹配
case 100: # 匹配100
print("奖励一辆车")
case 90: # 匹配90
print("奖励一台手机")
case 80: # 匹配80
print("奖励一个ipad")
case _: # 匹配其他
print("没有奖励")
逻辑运算符
| 运算符 | 描述 | 示例 |
|---|---|---|
| and | 与运算符 | x and y |
| or | 或运算符 | x or y |
| not | 非运算符 | x not y |
函数
函数是将一段实现功能的完整代码,使用函数名称进行封装通过函数名称进行调用。以此达到一次编写,多次调用的目的。 函数可以接受参数,也可以返回值。 函数可以嵌套,也可以递归。
# 定义函数
def get_sum(num):
s=0
for i in range(1,num+1):
s+=i
print(s)
return s # 返回值 非必须
# 调用函数
get_sum(10)
get_sum(100)
# 传参规则
def person(name,age,sex): # 位置参数
print(name,age,sex)
# 调用函数
person('张三',18,'男') # 默认位置参数
person(age=18,name='张三',sex='男') # 关键字参数
# 位置参数和关键字参数混合使用,*位置参数必须在关键字参数前面*
person('张三',18,sex='男')
函数参数的默认值
- 默认位置参数
- 位置参数和关键字参数混合使用,位置参数必须在关键字参数(默认值参数)前面
def handsome(name='miss-tree',age=30):
print('祝'+name,'天天快乐')
print(str(age)+'岁 生日快乐')
handsome()
handsome('中国',80)
handsome(18) # 默认传给了name TypeError: can only concatenate str (not "int") to str
# 可变参数 解包
def somefun(*args): # 可变参数 *args 表示可以接受任意数量的参数,args是一个元组
print(args)
for i in args:
print(i)
somefun(1,2,3,4,5,6,7,8,9)
somefun(*[,9,10,16,17,19,20]) # 解包 *表示解包 可以将元组、列表、字典等解包成多个参数
def somefun2(**kwargs): # 关键字参数 **kwargs 表示可以接受任意数量的关键字参数,kwargs是一个字典
print(kwargs)
for key,value in kwargs.items(): # 遍历字典
print(key,value)
somefun2(name='张三',age=18,sex='男')
somefun2(**{'name':'张三','age':18,'sex':'男'}) # 解包 **表示解包 可以将字典解包成多个关键字参数
可变参数的顺序 位置参数>可变参数(*args)>默认参数(xx=xx)>关键字参数(**kwargs)
变量的作用域
- 全局变量:在函数外部定义的变量,在整个程序中都可以访问。
- 在函数内部可以访问全局变量,但是不建议修改全局变量。
- 在函数内部可以使用 global 关键字声明变量为全局变量,但是不建议使用。
- global定义的全局变量和赋值要分开写,否则会报错。
def fun: global a # 定义全局变量或者引入外部的全局变量 a=10 # 赋值
- 局部变量:在函数内部定义的变量,只能在函数内部访问。
- 在函数内部可以访问局部变量。
- 在函数内部可以使用 nonlocal 关键字声明变量为非局部变量。
- nonlocal定义的非局部变量和赋值要分开写,否则会报错。
def fun: a = 10 def fun2: nonlocal a # 引入外层的局部变量 a=10 # 赋值- nonlocal 引入的外层变量,不能访问相邻的嵌套函数的局部变量。
闭包
闭包是指函数内部定义的函数,该函数可以访问外部函数的变量。
- 可以让变量常驻内存
- 可以让变量私有化,避免全局变量被修改
- 滥用闭包会导致程序的可读性变差和内存栈溢出,所以不建议过度使用闭包。
匿名函数
# 函数只有一行代码
def cale(a,b):
return a+b
# 使用匿名函数等价上面的代码
s=lambda a,b:a+b
print(cale(10,20))
print(s(10,20))
递归函数
递归函数是指在函数内部调用函数本身的函数。
def all(num):
if num<=1:
return 1
else:
return num*all(num-1)
print(all(6))
费波纳契数列
# 斐波那契数列
def fib(n):
if n==1 or n==2:
return 1
return fib(n-1)+fib(n-2)
print(fib(10)) # 55
装饰器
装饰器本质是一个闭包,在不修改原函数的情况下,对函数进行扩展的一种方式,而不需要修改原函数。
def guanjia(game):
def inner():
print('开外挂')
game()
print('关外挂')
return inner
def play_dnf():
print('又是美好的一天')
@guanjia
def play_lol():
print('德玛西亚!!!!!')
play_dnf = guanjia(play_dnf)
play_dnf()
# @guanjia 等价 play_dnf = guanjia(play_dnf)
play_lol()
# 装饰器
def warpper(func): # 装饰器函数
# * ** 表示可以接受任意数量的参数和关键字参数
def inner(*args,**kwargs): # 内部函数
print("装饰器函数") # 扩展功能
# * ** 表示把元组和字典打散成位置参数和关键字参数传递给原函数传递
ret = func(*args,**kwargs) # 调用原函数
print("装饰器函数") # 扩展功能
return ret # 返回原函数的返回值
return inner # 返回内部函数
@warpper # 装饰器
def fun(*args,**kwargs): # 原函数
print("原函数")
fun()
# 多个装饰器
def warpper1(func): # 装饰器函数
def inner(*args,**kwargs): # 内部函数
print("装饰器函数11") # 扩展功能
ret = func(*args,**kwargs) # 调用原函数
print("装饰器函数12") # 扩展功能
return ret # 返回原函数的返回值
return inner # 返回内部函数
def warpper2(func): # 装饰器函数
def inner(*args,**kwargs): # 内部函数
print("装饰器函数21") # 扩展功能
ret = func(*args,**kwargs) # 调用原函数
print("装饰器函数22") # 扩展功能
return ret # 返回原函数的返回值
return inner # 返回内部函数
# 装饰器就近原则,先执行warpper2,再执行warpper1
@warpper1 # 装饰器 执行func 实际上是 wrapper2.inner
@warpper2 # 装饰器 执行func
def fun(*args,**kwargs): # 原函数
print("原函数")
fun()
# 打印顺序 : 装饰器函数2 装饰器函数1 原函数 装饰器函数1 装饰器函数2
数学函数
| 函数名称 | 描述说明 |
|---|---|
| abs(x) | 获取x的绝对值 |
| divmod(x,y) | 获取x与y的商和余数 |
| max(sequence) | 获取sequence的最大值 |
| min(sequence) | 获取sequence的最小值 |
| sum(iter) | 对可迭代对象进行求和运算 |
| pow(x,y) | 获取x的y次幂 |
| round(x,d) | 对x进行保留d位小数,结果四舍五入 |
内置迭代函数
| 函数名称 | 描述说明 |
|---|---|
| sorted(iter) | 对可迭代对象进行排序 |
| reversed(sequence) | 反转序列生成新的迭代器对象 |
| zip(iter1,iter2) | 将iter1与iter2打包成元组并返回一个可迭代的zip对象 |
| enumerate(iter) | 根据iter对象创建一个enumerate对象 |
| all(iter) | 判断可迭代对象iter中所有元素的布尔值是否都为True |
| any(iter) | 判断可迭代对象iter中所有元素的布尔值是否都为False |
| next(iter) | 获取迭代器的下一个元素 |
| filter(function,iter) | 通过指定条件过滤序列并返回一个迭代器对象 |
| map(function,iter) | 通过函数function对可迭代对象iter的操作返回一个迭代器对象 |
# 内置迭代函数
# sorted(iter) 对可迭代对象进行排序
print(format(3.14,'20')) # 3.14
print(format(3.14,'.2f')) # 3.14
print(format('hello','20')) #
print(format('hello','*<20')) # hello***************
print(format('hello','*>20')) # ***************hello
print(format('hello','*^20')) # *******hello*******
异常处理
异常处理是指在程序运行过程中出现错误时,对错误进行处理的过程。
try: # 尝试执行
print(1/0) # 报错 ZeroDivisionError: division by zero
except ZeroDivisionError as e: # 捕获异常
print("除数不能为0") # 输出错误信息
except KeyError as e:
print("其他错误")
except ValueError as e:
print("其他错误")
else: # 没有异常时执行
print("没有异常") # 输出没有异常
finally: # 无论是否有异常都会执行
print("无论是否有异常都会执行")
| 异常类型 | 描述说明 |
|---|---|
| ZeroDivisionError | 当除数为0时,引发的异常 |
| IndexError | 索引超出范围所引发的异常 |
| KeyError | 字典取值时key不存在的异常 |
| NameError | 使用一个没有声明的变量时引发的异常 |
| SyntaxError | Python中的语法错误 |
| ValueError | 传入的值错误 |
| AttributeError | 属性或方法不存的异常 |
| TypeError | 类型不合适引发的异常 |
| IndentationError | 不正确的缩进引发的异常 |
关键字 raise 用于抛出异常。
try
raise Exception("这是一个异常") # 抛出异常
except Exception as e: # 捕获异常
print("捕获异常",e) # 输出捕获异常
程序断点
操作方式有多种:
- 在代码行前面点击鼠标左键,设置断点。
- 在代码行前面输入
import pdb; pdb.set_trace(),设置断点。 - 在代码行前面输入
breakpoint(),设置断点。 然后右键选择断点的蜘蛛形图标,选择Debug 'xxx.py'即可调试。或者在菜单栏上面点击蜘蛛形图标,选择Debug 'xxx.py'即可调试。
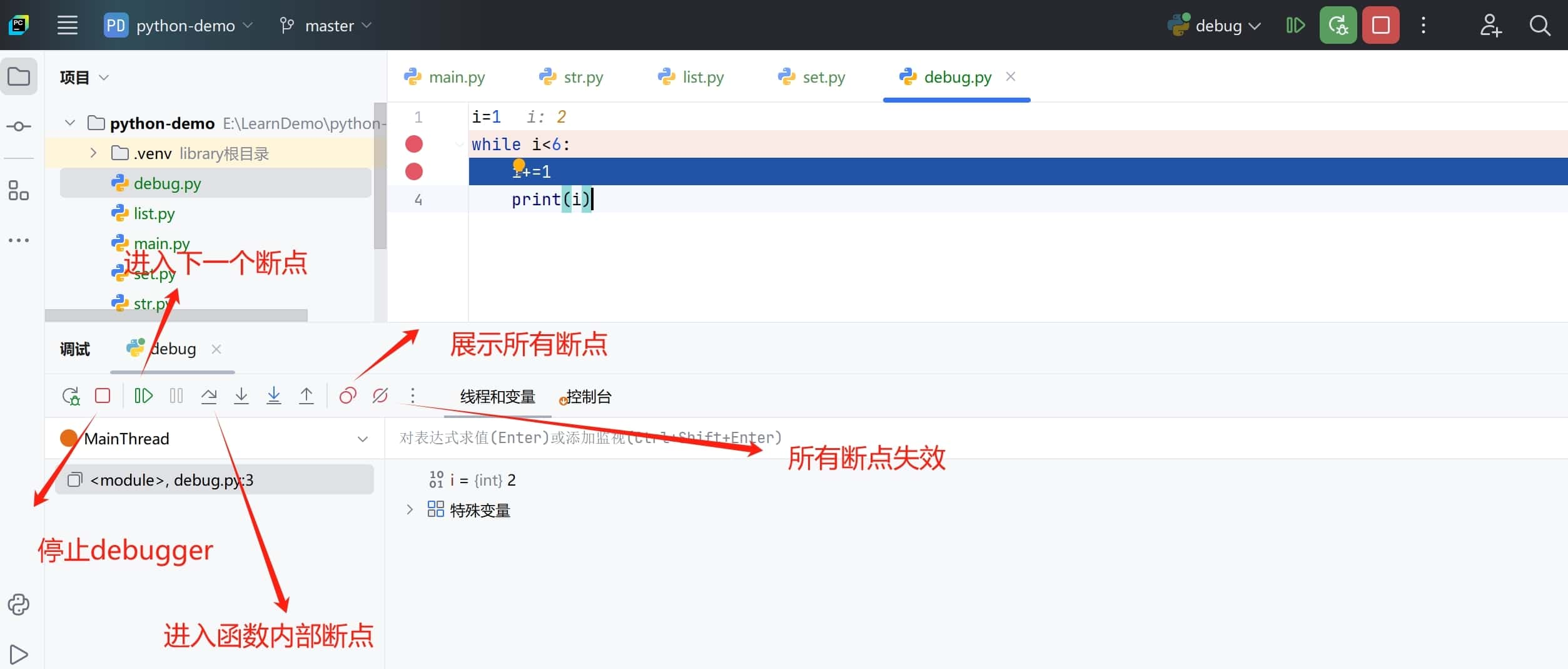
在上图的进入函数断点的四个箭头中,分别是:
- 单步运行程序但不步入函数
- 单步运行程序会进入函数,包括源代码
- 单步运行程序,会进入函数,只进入自己写的函数
- 跳出当前函数体
类和对象
类是对具有相同特征和行为的一组对象的抽象。 对象是类的实例化,是类的具体表现。
# 创建类实例
class Human():
school='航校'
# 相当于JavaScript中的constructor
def __init__(self,xm,age):
self.name = xm
self.age = age
# 静态方法
@staticmethod
def sm(self):
print('这是一个静态方法,不支持调用实例属性,也不支持调用实例方法')
def describe(self):
print(f'我叫{self.name},来自{self.school},今年{self.age}岁')
def extendMethod(self):
# 给类动态添加方法一定要加 self 参数,因为把一个函数绑定到类或者实例时,Python 会自动把实例本身当作第一个参数传递给这个函数,也就是self参数。
print('我是类动态创建的方法')
student = Human('张飞',33)
student.sm()
student.describe()
def dynamic():
print('我是动态创建的方法')
student.dynamic = dynamic
student.dynamic()
Human.extendMethod = extendMethod
student.extendMethod()
class Animals():
def __init__(self,name,food):
self.name=name # 普通的实例属性,类的内部、外部、及子类都可以访问
self._name='保护的名称-'+name # self._name是受保护的,只能本类和子类访问
self.__name='私有--'+name # self.__name表示私有的,只能类本身内部去访问
self.food=food
def _func(self):# 受保护的
print('本身及子类访问')
def __staticFn(self):# 私有的
print('只有定义的类可以访问')
def public(self):
print('这是普通的实例方法')
self._func()
self.__staticFn()
print(self._name)
print(self.__name)
cat = Animals('加菲','鱼')
# cat.public()
# print(cat.__name)# AttributeError: 'Animals' object has no attribute '__name'.
print(cat._name)
# print(Animals.__name)# AttributeError: type object 'Animals' has no attribute
# print(Animals.__staticFn)# AttributeError: type object 'Animals' has no attribute '__staticFn'
# print(cat.__staticFn)# AttributeError: 'Animals' object has no attribute '__staticFn'
要想访问类实例的私有属性,可以通过类实例的__dict__属性来访问。因为__dict__属性是一个字典,所以可以通过字典的方式来访问私有属性。
print(dir(cat)) # 查看类实例的属性和方法是可以访问的
# ['_Animals__name', '_Animals__staticFn', '__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getstate__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', '_func', '_name', 'food', 'name', 'public']
# 所以访问类实例的私有属性方式如下:
print(cat._Animals__name) # 私有--加菲
| 运算符 | 特殊方法 | 功能描述 |
|---|---|---|
| + | _add_() | 执行加法运算 |
| - | _sub _() | 执行减法运算 |
| >,>=,== | _lt _(), _le _(), _eq _() | 执行比较运算 |
| <,<=,!= | _gt _(), _ge _(), _ne _() | 执行比较运算 |
| *,/ | _mul _(), _truediv _() | 执行乘法运算,非整除运算 |
| %,// | _mod _(), _floordiv _ | 执行取余运算,整除运算 |
| ** | _pow _() | 执行幂运算 |
a,b=1,2
print(a+b) # 3
print(a.__add__(b)) # 3
print(a.__lt__(b)) # True
print(a.__eq__(b)) # False
print(a.__truediv__(b)) # 0.5
print(a.__floordiv__(b)) # 0
``
> 修改类实例的私有属性
```python
class Human():
def __init__(self,xm,sex):
self.name = xm
self.gender = sex
# 静态方法
@property # 装饰器 把方法变成属性 可以直接访问
def gender(self): # 定义一个方法,用来获取性别
return self._gender # 返回性别
@gender.setter # 装饰器 把方法变成属性 可以直接赋值
def gender(self,value): # 定义一个方法,用来设置性别
if value=='男' or value=='女': # 判断性别是否合法
self._gender = value # 设置性别
stu = Human('张三','男')
print(stu.gender) # 男
stu.gender = '女'
print(stu.gender) # 女
特殊属性
| 特殊属性 | 功能描述 |
|---|---|
| obj._dict_ | 对象的属性字典 |
| obj._class_ | 对象所属的类 |
| obj._bases_ | 类的父类元组 |
| obj._base_ | 类的父类 |
| obj._mro_ | 类的层次结构 |
| obj._subclasses_() | 类的子类列表 |
继承
继承是面向对象编程的一个重要概念,它允许一个类继承另一个类的属性和方法。
class Person():
def __init__(self,name,age):
self.name=name
self.age=age
def descibe(self):
print(f'我叫{self.name},今年{self.age}')
class Student(Person):
def __init__(self,name,age):
# 继承父类的实例属性
super().__init__(name,age)
self.name=name
stu=Student('刘表',33)
stu.descibe()
# 多继承
class Doctor():
def __init__(self,name,age):
self.name=name
self.age=age
def whoIm(self):
print('我是父类Doctor方法')
# 可以继承多个父类,用逗号分隔
class Kinds(Person,Doctor):
def __init__(self,name,age,num):
# 继承父类的实例属性
Person.__init__(self,name,age)
Doctor.__init__(self,name,age)
self.num=num
def descibe(self):# 父类方法重写
# 可选:调用父类方法继承 不继承也可以完全重写
Person().descibe()
print(f'我叫{self.name},今年{self.age},学号是{self.num}')
daughter = Kinds('刘亦菲',33,201306213456)
daughter.descibe()
daughter.whoIm()
# 查看继承关系
print(Kinds.__bases__) # (<class '__main__.Person'>, <class '__main__.Doctor'>)
print(Kinds.__base__) # <class '__main__.Person'>
print(Kinds.__mro__) # (<class '__main__.Kinds'>, <class '__main__.Person'>, <class '__main__.Doctor'>, <class 'object'>)
# 查看子类列表
print(Person.__subclasses__()) # [<class '__main__.Student'>, <class '__main__.Kinds'>]
在继承多个父类有同名方法时,会按照继承顺序查找方法。默认调用第一个查找到的方法。若是怕此类方式不好用可以重写方法,或者在重写方法中继承指定父类的方法。
类的深拷贝和浅拷贝
| 分类 | 描述 |
|---|---|
| 赋值 | 只是形成两个变量,实际上还是指向同一个对象 |
| 浅拷贝 | 拷贝时,对象包含的子对象内容不拷贝,因此源对象与拷贝对象会引用同一个子对象 |
| 深拷贝 | 使用copy模块的deepcopy函数,递归拷贝对象中包含的子对象源对象和拷贝对象所有的子对象也不相同 |
class Cpu():
pass
class Disk():
pass
class Computer():
def __init__(self,cpu,disk):
self.cpu=cpu
self.disk=disk
cpu=Cpu()
disk=Disk()
# 赋值
com = Computer(cpu,disk)
# com1=com
# print('com和com1的cpu是否相同',com1.cpu==com.cpu) # True
# print('com和com1的disk是否相同',com1.disk==com.disk) # True
# 浅拷贝
import copy
com2 = copy.copy(com)
print('com和com2的cpu是否相同',com2.cpu==com.cpu) # True
print('com和com2的disk是否相同',com2.disk==com.disk) # True
# 浅拷贝
com3 = copy.deepcopy(com)
print('com和com2的cpu是否相同',com3.cpu==com.cpu) # False
print('com和com2的disk是否相同',com3.disk==com.disk) # False