
python 进阶
模块
在整个python中,一个.py文件就是一个模块,模块的名字就是文件名。在引入模块时,默认是在项目中查找模块和包名。
模块的导入方式
- 导入整个模块:import module_name [as alias]
- 导入特定的函数:from module_name import function_name
- 导入模块中的所有函数:from module_name import *|func|{变量名}
# 导入的模块包含模块内的变量、函数、类等,自己写的.py文件也可以作为模块导入
import module_name [as alias]
module_name.function_name()
alias.function_name()
from module_name import function_name
function_name()
from module_name import *|func|{变量名}
function_name()
# 若是以 * 导入,会导入所有的函数、变量等,然后直接使用函数、变量
function_name()
# 若是函数名与自己定义的函数名相同,会覆盖掉
# 解决办法:将两个模块相同的文件以模块名区分,然后通过模块名调用方法
import module_name
import module_name2
module_name.function_name()
module_name2.function_name()
# 查找模块包名
my_project
├── project_dir
├──sys
│ └──my_module.py
import sys.my_module as a
# 上面的意思是查找文件夹 sys 下的模块 my_module ,然后将其重命名为 a 进行调用
# 若是引入的模块与当前编辑的文件在同一个目录下,直接使用模块名进行调用
# 同层级加目录会报(注意:模块名不能以数字开头)
# ModuleNotFoundError: No module named 'my_module'
模块的导入问题 一般来说,依赖或者公共模块内都没有立即执行或者打印的语句,但是在自定义的模块或者调用他人的模块时,会出现打印的语句,这是因为导入模块时,会执行模块内的语句。 解决办法:
- 模块内的语句放在 if name == 'main' 内,然后调用函数
if __name__ == '__main__'
# 模块内的语句,将之前的代码放到下面
常见模块
在安装python时,会自带一些模块,这些模块可以直接使用。比如在pycharm中,项目文件下外部库的lib文件夹下,就是python自带的模块。 常见的模块有:
- os:操作系统相关的模块
- sys:系统相关的模块
- time:时间相关的模块
- datetime:日期时间相关的模块
- random:随机数相关的模块
- math:数学相关的模块
- json:json相关的模块
- re:正则表达式相关的模块
- collections:集合相关的模块
- functools:函数相关的模块
- itertools:迭代器相关的模块
- multiprocessing:多进程相关的模块
- threading:多线程相关的模块
- asyncio:异步IO相关的模块
- aiohttp:异步HTTP相关的模块
- requests:HTTP相关的模块
- beautifulsoup4:HTML解析相关的模块
- selenium:自动化测试相关的模块
- pytest:测试框架相关的模块
- flask:Web框架相关的模块
- django:Web框架相关的模块
- sqlalchemy:数据库ORM相关的模块
- pymysql:MySQL数据库相关的模块
- pymongo:MongoDB数据库相关的模块
- redis:Redis数据库相关的模块
- celery:任务队列相关的模块
- celerybeat:定时任务相关的模块
- celeryd:任务执行器相关的模块
- celeryflower:任务监控相关的模块
- celerycam:任务监控相关的模块
- celeryev:任务监控相关的模块
- celerymon:任务监控相关的模块
- celeryworker:任务执行器相关的模块
random模块 是Python中用于产生随机数的标准库
| 函数名称 | 功能描述 |
|---|---|
| seed(x) | 初始化给定的随机数种子,默认为当前系统时间 |
| random() | 产生一个[0.0,1.0)之间的随机小数 |
| randint(a,b) | 生成一个[a,b]之间的整数 |
| randrange(m,n,k) | 生成一个[m,n)之间步长为k的随机整数 |
| uniform(a,b) | 生成一个[a,b]之间的随机小数 |
| choice(seq) | 从序列中随机选择一个元素 |
| shuffle(seq) | 将序列seq中元素随机排列,返回打乱后的序列 |
import random
# 初始化给定的随机数种子,默认为当前系统时间
random.seed(10)
# 随机验证码
# 随机生成一个6位的验证码,包含数字和字母
def random_num():
return str(random.randint(0,9)) # 数字
def random_upper():
return chr(random.randint(65,90)) # 大写字母
def random_lower():
return chr(random.randint(97,122)) # 小写字母
# 随机生成一个6位的验证码,包含数字和字母
def random_verify_code(n=6):
lt = []
for i in range(n):
which=random.randint(1,3) # 随机生成1,2,3
if which==1:
lt.append(random_num())
elif which==2:
lt.append(random_upper())
else:
lt.append(random_lower())
return ''.join(lt) # 将列表转换为字符串
print(random_verify_code(6))
time模块 是Python中提供的用于处理时间的标准库,可以用来进行时间处理、时间格式化和计时等
| 函数名称 | 功能描述 |
|---|---|
| time() | 获取当前时间戳 |
| localtime(sec) | 获取指定时间戳对应的本地时间的struct time对象 |
| ctime() | 获取当前时间戳对应的易读字符串 |
| strftime() | 格式化时间,结果为字符串 |
| strptime() | 提取字符串的时间,结果为struct time对象 |
| sleep(sec) | 休眠sec秒 |
import time
# 获取当前时间戳
t=time.time()
print(t)
# 获取当前时间戳对应的本地时间的struct time对象
lt=time.localtime(t)
print('年:',lt.tm_year)
print('月:',lt.tm_mon)
print('日:',lt.tm_mday)
print('小时:',lt.tm_hour)
datetime模块可以更方便的显示日期并对日期进行运算。
| 函数名称 | 功能描述 |
|---|---|
| datetime.datetime | 表示日期时间的类 |
| datetime.timedelta | 表示时间间隔的类 |
| datetime.date | 表示目期的类 |
| datetime.time | 表示时间的类 |
| datetime.tzinfo | 时区相关的类 |
import datetime
# 获取当前日期时间
now=datetime.datetime.now()
print(now)
t1=datetime.datetime(2023,10,2,22,10,43)
diff=now - t1
print(diff.get_days()) # 间隔的天数
print(diff.total_seconds()) # 间隔实际的秒数
cur=now.strftime('%Y年-%m月-%d日 %H:%M:%S') # 格式化日期时间
s1=input('请输入日期时间(格式:2023-10-02 22:10:43):')
t2=datetime.datetime.strptime(s1,'%Y-%m-%d %H:%M:%S') # 提取字符串的时间,结果为struct time对象
print(t2)
pickle模块 是Python中用于序列化和反序列化对象的标准库,可以将Python对象转换为字节流,然后将其保存到文件中,或者从文件中读取字节流,然后将其转换为Python对象。 | 函数名称 | 描述说明| | --- | --- | | dumps(obj) | 把对象(数据)转化为字节,编码过程 | | loads(s) | 把字节转化为数据,解码过程 | | dump(obj,file) | 与dumps()功能相同,把对象序列化成字节存储到文件file中 | | load(file) | 与loads()功能相同,从文件file中字节反序列化成对象数据 | | | |
json模块的常用函数 | 函数名称 | 描述说明| | --- | --- | | json.dumps(obj) | 将Python数据类型转成JSON格式过程,编码过程 | | json.loads(s) | 将JSON格式字符串转成Python数据类型,解码过程 | | json.dump(obj,file) | 与dumps()功能相同,将转换结果存储到文件file中 | | json.load(file) | 与loads()功能相同,从文件file中读入数据 | | | |
import json
# 将Python数据类型转成JSON格式过程,编码过程
d1={"name":"huixiangwuyou","age":18}
s1=json.dumps(d1) # 将字典转换为字符串
print(s1) # {"name":"huixiangwuyou","age":18}
# 将JSON格式字符串转成Python数据类型,解码过程
d2=json.loads(s1) # 将字符串转换为字典
print(d2) # {'name': 'huixiangwuyou', 'age': 18}
hashlib模块 是Python中用于加密的标准库,可以用于生成各种哈希算法的摘要。
import hashlib
# 生成md5摘要
m=hashlib.md5()
m.update('hello'.encode('utf-8')) # 加密
print(m.hexdigest()) # 16进制
# 解决MD5的撞库问题
# 1. 加盐:在密码的前面或者后面添加一些随机的字符串,然后再进行加密
mm=hashlib.md5(d'qweqrerwtqwe34564q65w4e5qw')
mm.update('hello'.encode('utf-8')) # 加密
print(m.hexdigest())
# 生成sha1摘要
s=hashlib.sha1()
s.update('hello'.encode('utf-8')) # 加密
print(s.hexdigest()) # 16进制
shutil模块 是Python中用于文件和目录操作的标准库,可以用于复制、移动、删除、压缩和解压缩文件等操作。
import shutil
# 复制文件
shutil.copy('hello.txt','hello2.txt') # 复制文件
shutil.copyfile('hello.txt','hello2.txt') # 只复制文件信息,不包含文件权限
# 复制目录
shutil.copytree('dir1','dir2') # 复制目录
# 移动文件
shutil.move('hello.txt','dir1') # 移动文件
# 移动目录
shutil.move('dir1','dir2') # 移动目录
# 删除文件
shutil.rmtree('dir1') # 删除目录
logging模块 是Python中用于记录日志的标准库,可以用于记录程序的运行日志,方便调试和排查问题。
- level=logging.INFO 日志级别,INFO表示记录信息、警告、错误、严重错误
- format='%(asctime)s - %(name)s - %(levelname)s - %(message)s' 日志格式
- asctime 时间,name 模块名,levelname 日志级别,message 日志信息
- 日志级别:DEBUG、INFO、WARNING、ERROR、CRITICAL
- 日志级别从低到高,依次为:DEBUG、INFO、WARNING、ERROR、CRITICAL
- 当设置日志级别为INFO=10时,只会记录INFO、WARNING、ERROR、CRITICAL级别的日志
- 当设置日志级别为WARNING=30时,只会记录WARNING、ERROR、CRITICAL级别的日志
- 当设置日志级别为ERROR=40时,只会记录ERROR、CRITICAL级别的日志
- 当设置日志级别为CRITICAL=50时,只会记录CRITICAL级别的日志
- filename='example.log' 日志文件的路径和文件名
- filemode='a' 日志文件的打开模式,a表示追加模式,w表示覆盖模式
- datefmt='%Y-%m-%d %H:%M:%S' 日志时间的格式
- formatters 日志格式
- handlers 日志处理器,用于将日志输出到不同的地方,比如文件、控制台、邮件等
- loggers 日志记录器,用于记录日志
- filters 日志过滤器,用于过滤日志
- 日志处理器的常用函数:
- addHandler(handler):添加日志处理器
- removeHandler(handler):移除日志处理器
- setLevel(level):设置日志级别
- 日志记录器的常用函数:
- addHandler(handler):添加日志处理器
import logging
logging.basicConfig(level=30.INFO,format='%(asctime)s - %(name)s - %(levelname)s - %(message)s')
# 记录日志
logging.info('hello world') # 记录信息
logging.warning('hello world') # 记录警告
logging.error('hello world') # 记录错误
logging.critical('hello world') # 记录严重错误
traceback模块 是Python中用于获取异常信息的标准库,可以用于获取异常信息,方便调试和排查问题。
import traceback
try:
1/0
except Exception as e:
print(e) # 输出异常信息
print(traceback.format_exc()) # 输出异常信息
# 输出异常信息到文件 或者是logging模块处理
with open('error.log','a') as fp:
fp.write(traceback.format_exc())
zipfile模块 是Python中用于压缩和解压缩文件的标准库,可以用于压缩和解压缩文件,方便文件的传输和存储。
import zipfile
# 压缩文件
with zipfile.ZipFile('hello.zip','w') as zf:
zf.write('a.txt') # 压缩文件
zf.write('b.txt') # 压缩文件
# 解压文件
f=zipfile.ZipFile('zip_dir/abc.zip',mode='r')
# 直接全部解压
# f.extractall("zip_dir/abcd")
for item in f.namelist():
f.extract(item,"zip_dir/all")
f.close()
第三方模块
在python中,第三方模块是由社区提供的模块,这些模块可以直接使用,不需要自己编写。 第三方模块的安装卸载和升级方式:
- pip install module_name
- pip install module_name==version
- pip install module_name>=version # 安装指定版本或更高版本的模块
- pip install module_name<=version # 安装指定版本或更低版本的模块
- pip install module_name~=version # 安装指定版本或相近版本的模块
- pip install module_name==version --upgrade # 升级指定版本的模块
- pip install module_name==version --no-cache-dir # 不使用缓存安装指定版本的模块
- pip install module_name==version --user # 安装指定版本的模块到用户目录下
- pip install module_name http://pypi.douban.com/simple --trusted-host pypi.douban.com
- pip `uninstall` module_name # 卸载指定版本的模块
- pip install module_name --upgrade --force-reinstall # 强制升级指定版本的模块
- python -m pip install --upgrade pip # 使用Python升级pip工具
requests模块
requests模块是一个HTTP客户端库,它可以发送HTTP请求并获取响应。 requests模块的常用函数:
- get(url, params=None, **kwargs):发送GET请求,返回响应对象。
- post(url, data=None, json=None, **kwargs):发送POST请求,返回响应对象。
- put(url, data=None, **kwargs):发送PUT请求,返回响应对象。
- delete(url, **kwargs):发送DELETE请求,返回响应对象。
- head(url, **kwargs):发送HEAD请求,返回响应对象。
import requests
url="https://blog.huixiangwuyou.com"
url2="https://kodo.huixiangwuyou.com/blog/images/mysql.jpeg"
resp = requests.get(url2)
resp.encoding='utf-8'
# print(resp.text) # 获取 html
print(resp.content) # 若是爬取是图片获取 二进制
with open("load.jpeg","wb") as fp:
fp.write(resp.content)
openpyxl模块
openpyxl模块是一个用于读写Excel文件的Python库。 openpyxl模块的常用函数:
- load_workbook(filename):加载Excel文件,返回工作簿对象。
- Workbook():创建新的工作簿对象。
- create_workbook():创建新的工作簿对象。
- save(filename):保存工作簿对象到文件。
- active:获取活动工作表。
- create_sheet(title, index):创建新的工作表,title为工作表标题,index为工作表索引。
- delete_sheet(sheet):删除指定的工作表。
- sheetnames:获取所有工作表的名称。
- sheet1 = wb['Sheet1']:获取指定名称的工作表。
- sheet1 = wb.active:获取活动工作表。
- cell(row, column, value):获取或设置指定单元格的值。
# 创建新的工作表
from openpyxl import Workbook
cj=[
['姓名','语文','数学','英语'],
['李世民', '100', '75', '59'],
['刘备', '90', '65', '95']
]
wb = Workbook()
sheet = wb.create_sheet('班级学生成绩单')
for item in cj:
sheet.append(item)
wb.save('abs.xlsx')
from openpyxl import load_workbook
# 打开工作簿
wb = load_workbook('abs.xlsx')
# 获取活动工作表
# sheet = wb['班级学生成绩单']
sheet = wb['Sheet']
# 获取单元格的值
cell_value = sheet['A1'].value
# 设置单元格的值
sheet['A1'] = 'Hello, World!'
# 保存工作簿 不能打开文件,否则报错:PermissionError: [Errno 13] Permission denied: 'abs.xlsx'
wb.save('abs.xlsx')
pdfplumber模块
pdfplumber模块是一个用于解析PDF文件的Python库。 pdfplumber模块的常用函数:
- open(filename):打开PDF文件,返回PDF对象。
- pages:获取所有页面。
- extract_text():提取文本。
- extract_table():提取表格。
- extract_images():提取图像。
- extract_graphics():提取图形。
import pdfplumber
# 打开PDF文件
pdf = pdfplumber.open('abs.pdf')
# 获取所有页面
pages = pdf.pages
# 提取文本
text = pages[0].extract_text()
# 提取图像
images = pages[0].extract_images()
# 提取图形
graphics = pages[0].extract_graphics()
# 关闭PDF文件
pdf.close()
import pdfplumber
with pdfplumber.open('git.pdf') as fp:
for i in fp.pages:
print(i.extract_text()) # extract_text()获取内容
print(f'第---{i.page_number}页')
numpy模块 matplotlib模块
numpy模块是一个用于科学计算的Python库。 numpy模块的常用函数:
- array():创建数组。
- zeros():创建全0数组。
- ones():创建全1数组。
- full():创建指定值数组。
- arange():创建等差数列。
- linspace():创建等间隔数组。
- random():创建随机数组。
- reshape():改变数组形状。
- transpose():转置数组。
- concatenate():合并数组。
- split():分割数组。
- sort():排序数组。
- searchsorted():查找元素位置。
- unique():去重数组。
- where():查找元素位置。
- sum():求和。
- mean():求平均值。
- std():求标准差。
- var():求方差。
- max():求最大值。
- min():求最小值。
- argmax():求最大值位置。
- argmin():求最小值位置。
- dot():矩阵乘法。
- cross():向量积。
- outer():外积。
- matmul():矩阵乘法。
- vdot():向量点积。
- inner():向量内积。
- kron():克罗内克积。
matplotlib 模块是一个用于绘制图表的Python库。 matplotlib模块的常用函数:
- plot():绘制折线图。
- bar():绘制柱状图。
- hist():绘制直方图。
- scatter():绘制散点图。
- pie():绘制饼图。
- boxplot():绘制箱线图。
- contour():绘制等高线图。
- contourf():绘制填充等高线图。
- imshow():绘制图像。
- savefig():保存图像。
- show():显示图像。
- xlabel():设置x轴标签。
- ylabel():设置y轴标签。
- title():设置标题。
- legend():设置图例。
- grid():设置网格。
- xlim():设置x轴范围。
- ylim():设置y轴范围。
- xticks():设置x轴刻度。
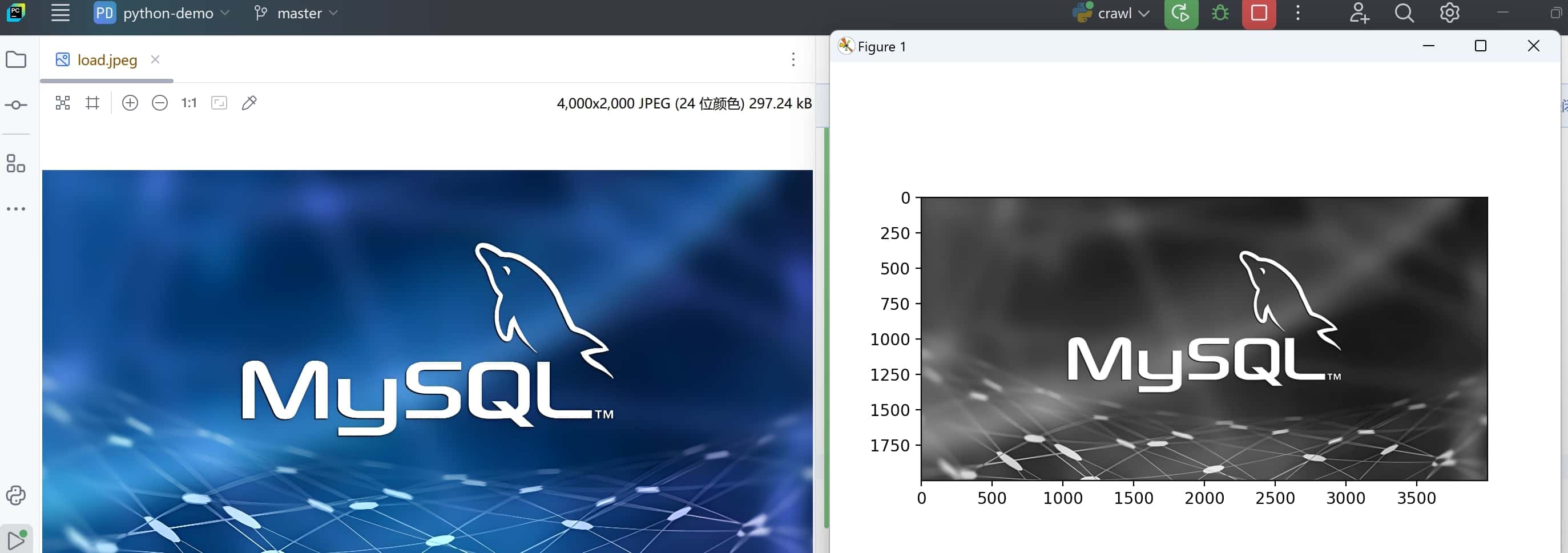
# 将图片变灰
import numpy as np
import matplotlib.pyplot as plt
# 读取图片
n1=plt.imread('load.jpeg')
print(n1)
# 三维数组,最高维度表示图像高,次维度表示图像宽,最低表示图像[R,G,B]颜色
plt.imshow(n1)
# 写一个灰度公式
n2=np.array([0.299,0.597,0.114])
x=np.dot(n1,n2)
# 传入数组显示灰度
plt.imshow(x,cmap='gray')
plt.show()
pandas模块
pandas模块是一个用于数据处理和分析的Python库。 pandas模块的常用函数:
- DataFrame():创建数据框。
- read_csv():读取CSV文件。
- read_excel():读取Excel文件。
- read_sql():读取SQL数据库。
- read_html():读取HTML文件。
- read_json():读取JSON文件。
- read_pickle():读取Pickle文件。
- read_hdf():读取HDF文件。
- read_feather():读取Feather文件。
- read_parquet():读取Parquet文件。
- read_gbq():读取BigQuery文件。
- read_sql_table():读取SQL数据库表。
- read_sql_query():读取SQL数据库查询结果。
- read_sql_schema():读取SQL数据库表结构。
- read_sql_table():读取SQL数据库表。
- read_sql_query():读取SQL数据库查询结果。
- read_sql_schema():读取SQL数据库表结构。
import pandas as pd
import matplotlib.pyplot as plt
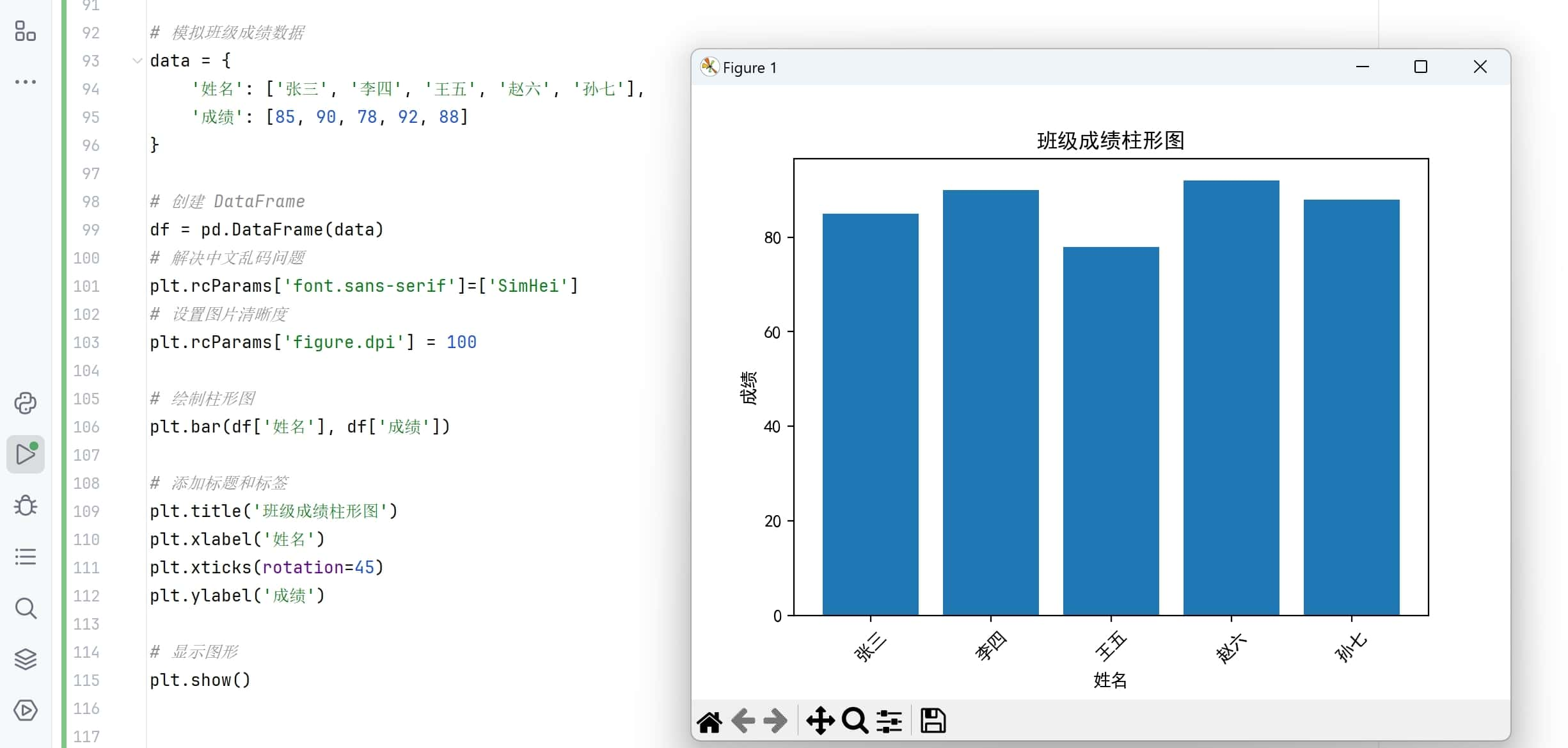
# 模拟班级成绩数据
data = {
'姓名': ['张三', '李四', '王五', '赵六', '孙七'],
'成绩': [85, 90, 78, 92, 88]
}
# 创建 DataFrame
df = pd.DataFrame(data)
# 解决中文乱码问题
plt.rcParams['font.sans-serif']=['SimHei']
# 设置图片清晰度
plt.rcParams['figure.dpi'] = 100
# 绘制柱形图
plt.bar(df['姓名'], df['成绩'])
# 添加标题和标签
plt.title('班级成绩柱形图')
plt.xlabel('姓名')
plt.xticks(rotation=45)
plt.ylabel('成绩')
# 显示图形
plt.show()
PyEchoCharts模块
PyEcharts是由百度开源的数据可视化库,它对流行图的支持度比较高,它给用户提供了30多种图形,如柱形渐变图K线周期图等 中文帮助文档:https://pyecharts.org/#/zh-cn/
PIL模块
PIL模块是Python Imaging Library的缩写,是Python中用于处理图像的库。
pip install pillow
PIL模块的常用函数:
- open():打开图像文件。
jieba模块
jieba模块是一个中文分词库,它可以将中文文本切分为词语。 jieba模块的常用函数:
- cut():分词。
PyInstaller模块
PyInstaller是可以在Windows操作系统中将Python源文件打包成.exe的可执行文件。还可以在Linux和Mac OS操作系统中对源文件进行打包操作。 打包的语法结构为: pyinstaller -F {源文件文件名.py} 注意事项: 在进行文件打包时,需要打包的文件尽量不要有中文,而且需要打包的文件路径也尽量不要有中文,路径中包含中文有可能会导致打包失败 PyInstaller模块的常用函数:
- freeze():打包。
OS模块
OS模块是Python中用于操作操作系统的标准库。 OS模块的常用函数:
- getcwd():获取当前工作目录。
- chdir():改变当前工作目录。
- listdir():列出指定目录下的所有文件和子目录。
- mkdir():创建目录。
- makedirs():创建多级目录。
- rmdir():删除目录。
- remove():删除文件。
- stat():获取文件状态信息。
- st_size:文件大小。
- st_mtime:文件修改时间。
- st_ctime:文件创建时间。
- st_atime:文件访问时间。
- rename():重命名文件或目录。
- system():运行系统命令。
- path.exists():判断路径是否存在。
- path.isfile():判断路径是否为文件。
- path.isdir():判断路径是否为目录。
- path.join():连接路径。
- path.split():分割路径。
- path.splitext():分割路径和扩展名。
- path.abspath():获取绝对路径。
- walk():遍历目录树。
- environ():获取环境变量。
- getenv():获取环境变量。