- Published on
python 服务
- Authors

- Name
- MissTree
服务器
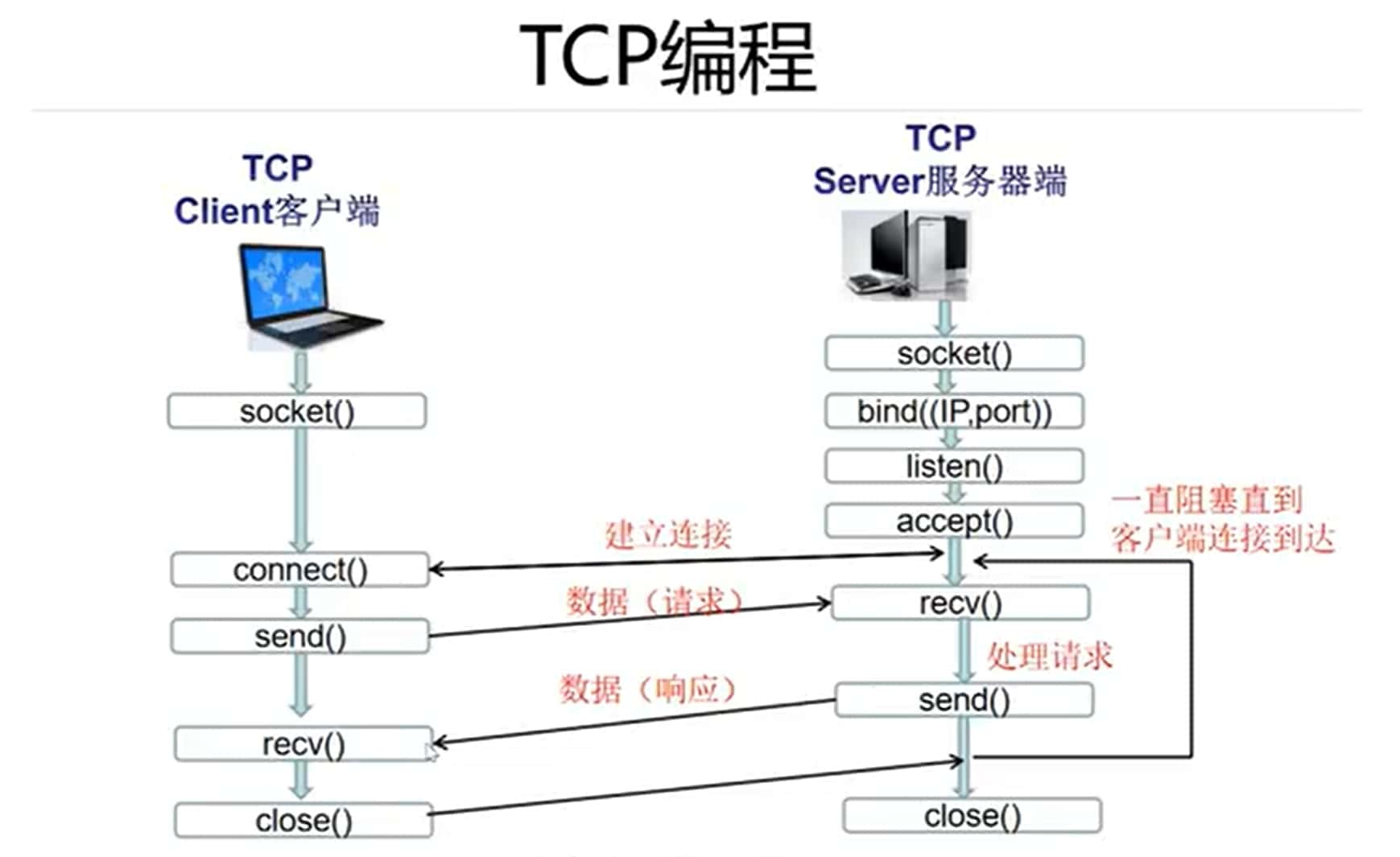
tcp服务
# 服务器端代码
from socket import socket,AF_INET,SOCK_STREAM
# AF_INET 用于 internet 进程的通信
# SOCK_STREAM tcp协议
# 创建socket对象
server = socket(AF_INET,SOCK_STREAM)
# 绑定IP地址和端口号
ip='127.0.0.1'
port=8090
server.bind((ip,port))
# 监听连接 设置最大连接数量为5
server.listen(5)
print('服务器启动')
# 接受客户端连接
client_socket, client_addr = server.accept()
# 接收客户端发送的数据
data = client_socket.recv(1024)
print('客户端发送过来的数据',data.decode('utf-8'))
# 建立多次通信
while data!='bye':
# 接收的数据
if data!='':
print('接收到的数据是',data)
# 发送数据
info=input("请输入发送客户端数据")
client_socket.send(info.encode('utf-8'))
if data=='bye':
break
data = client_socket.recv(1024).decode('utf-8')
# 关闭连接
client_socket.close()
server.close()
# 客户端代码 在pycharm中创建新窗口运行新项目
from socket import socket,AF_INET,SOCK_STREAM
# AF_INET 用于 internet 进程的通信
# SOCK_STREAM tcp协议
# 客户端创建socket对象
client = socket()
# 绑定服务端IP地址和端口号
ip='127.0.0.1'
port=8090
client.connect((ip,port))
# 监听连接
print('------与服务器建立连接-----')
# 发送数据给服务器端
client.send('Hello, client!'.encode('utf-8'))
#多次通信
info=''
while info!='bye':#假设输入bye就是关闭通信
# 准备发送的数据
send_data=input('请输入对服务端的通信')
client.send(send_data.encode('utf-8'))
if info=='bye':
break
# 接收一条数据
info=client.recv(1024).decode('utf-8')
print('响应的数据:',info)
# 关闭连接
client.close()
建立连接前要求服务端先启动,否则会报错:ConnectionRefusedError: [WinError 10061] 由于目标计算机积极拒绝,无法连接。
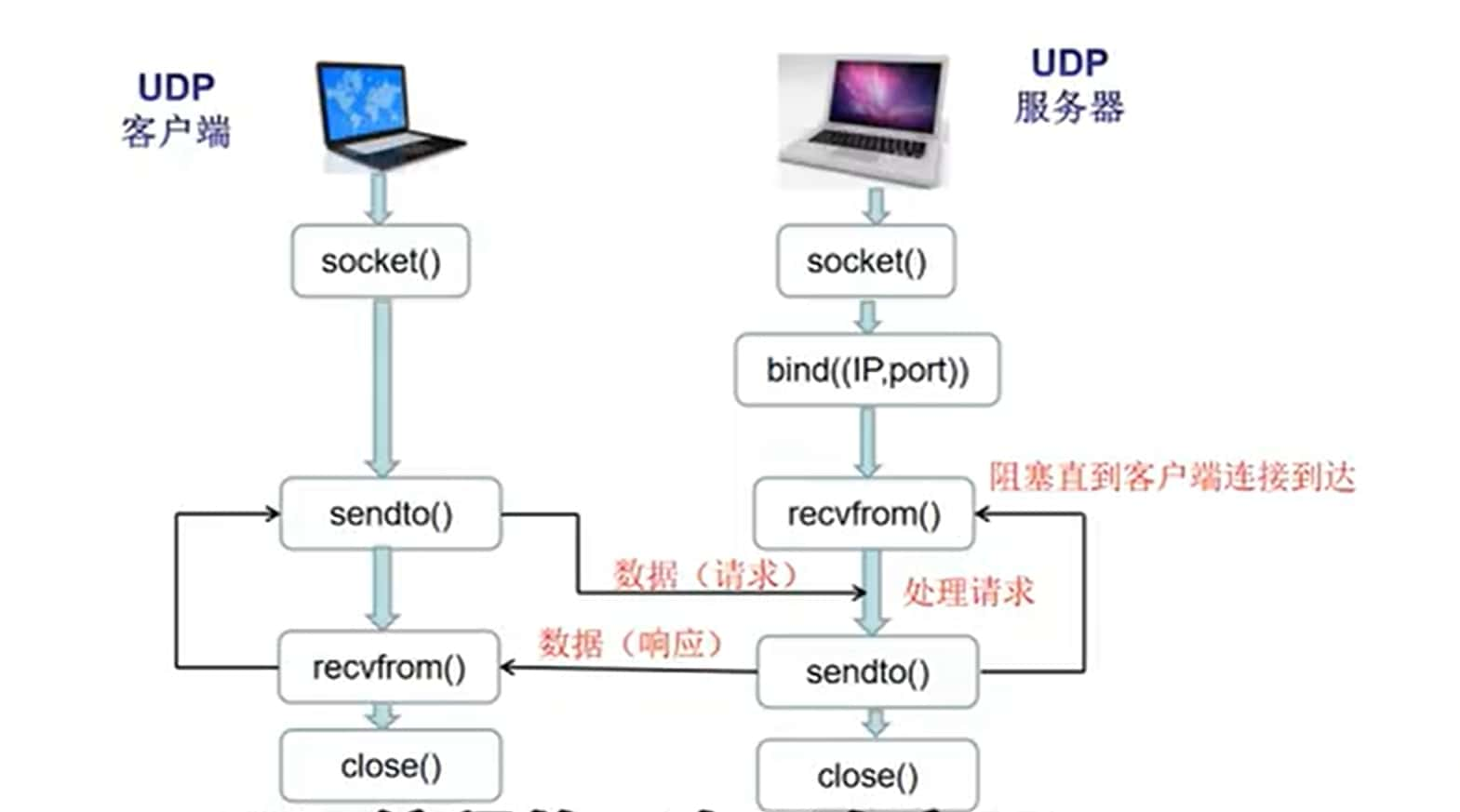
udp服务
# 服务器端代码
from socket import socket,AF_INET,SOCK_DGRAM
# AF_INET 用于 internet 进程的通信
# SOCK_STREAM UDP协议
# 创建socket对象
send_server = socket(AF_INET,SOCK_DGRAM)
# 指定接收端IP地址和端口号
ip_port=('127.0.0.1',8090)
# 发送数据
data=input("发送数据")
# 监听连接
send_server.sendto(data.encode('utf-8'),ip_port)
print('服务器启动')
# 接受客户端信息
client_data, client_addr = send_server.recvfrom(1024)
# 接收客户端发送的数据
print('接收到的数据',client_data.decode('utf-8'))
# 关闭连接
send_server.close()
# 客户端代码 在pycharm中创建新窗口运行新项目
from socket import socket,AF_INET,SOCK_DGRAM
# AF_INET 用于 internet 进程的通信
# SOCK_STREAM tcp协议
# 客户端创建socket对象
client = socket(AF_INET,SOCK_DGRAM)
# 绑定服务端IP地址和端口号
ip='127.0.0.1'
port=8090
client.bind((ip,port))
# 接收数据
print('------等待接收数据-----')
rece_data,addr=client.recvfrom(1024)
print('接收到的数据:',rece_data.decode('utf-8'))
# 发送数据给服务器端
callbackmsg=input('请输入回复数据')
client.sendto(callbackmsg.encode('utf-8'),addr)
# 关闭连接
client.close()
进程
是程序在操作系统中的一次执行过程,是系统进行资源分配和调度的基本单位。每个进程都有自己独立的内存空间、系统资源(如文件描述符)等。
# 进程
from multiprocessing import Process
Process(group=None,target=None,name=None,args=(),kwargs={})
线程
每个进程都可能有多个线程,线程是进程中的一个执行单元,是 CPU 调度和分派的基本单位。因为线程共享进程的资源,线程间的通信更加方便,可以直接访问共享的内存变量,而且线程是无序的。但这也带来了一些问题,需要使用同步机制(如锁、信号量等)来保证数据的一致性。
线程问题:
- 购买车票时,多个线程同时购买同一张票,因为判断还有票导致票被多个人抢
from threading import Thread
import time
import os
def func(name):
for i in range(10):
time.sleep(1)
print(name,i,f'当前进程为{os.getpid()},父进程为{os.getppid()}')
if __name__ == '__main__':
#创建线程
t1 = Thread(target=func,args=('刘秀',))
t2 = Thread(target=func,args=('赵匡胤',))
t3 = Thread(target=func,args=('李世民',))
t1.start()
t2.start()
t3.start()
class MyThread(Thread):
def __init__(self,name):
super(MyThread,self).__init__()
self.name=name
def run(self):
for i in range(10):
time.sleep(1)
print(self.name,i,f'当前进程为{os.getpid()},父进程为{os.getppid()}')
if __name__ == '__main__':
#创建线程
t1 = MyThread('刘秀22')
t2 = MyThread('赵匡胤33')
t3 = MyThread('李世民444')
t1.start()
t2.start()
t3.start()
# 线程锁
from multiprocessing import Pool
from threading import Thread,Lock,current_thread
import time,os,threading
# 售票数量
tickets=50
lock=Lock()
def sale_ticket():
global tickets
#每个窗口有100人排队
for i in range(100):
lock.acquire_lock()#上锁
if tickets>0:
print(f'{current_thread().name}正在售第{tickets}张票')
tickets-=1
time.sleep(0.5)
lock.release_lock()#解锁
if __name__=='__main__':
for i in range(3):
t=Thread(target=sale_ticket)
t.start()
线程池
| 方法名 | 功能描述 |
|---|---|
| apply_async(func,args,kwargs) | 使用非阻塞方式(异步方式)调用函数func |
| apply(func,args,kwargs) | 使用阻塞方式(同步方式)调用函数func |
| close() | 关闭进程池,不再接收新任务 |
| terminate() | 不管任务是否完成,立即终止 |
| join() | 阻塞主进程,必须在terminate()或close()之后使用 执行完线程池任务再执行后续代码 |
# 线程池
from multiprocessing import Pool
import time,os
def task(name):
print(name,f'当前线程为{os.getpid()},父进程为{os.getppid()}')
time.sleep(1)
if __name__ == '__main__':
start=time.time()
print("*"*20,start,"*"*20)
# 创建线程池
p=Pool(3)
#创建线程
for i in range(10):
p.apply_async(func=task,args=(i,))
# 关闭线程池,不再接收新任务
p.close()
# 阻塞主进程 等执行完计算时间
p.join()
print(time.time()-start)
# 线程池 支持遍历和线程回调
from concurrent.futures import ThreadPoolExecutor
def func(name):
return name
def call_back(value):
print('*'*10,value.result())
if __name__ == '__main__':
with ThreadPoolExecutor(10) as t:
t.submit(func,'屌毛').add_done_callback(call_back)
t.submit(func,'沙雕').add_done_callback(call_back)
# 或者使用 map
with ThreadPoolExecutor(10) as t:
for i in t.map(func,['111','222','333']):
print(i)
Pool和ThreadPoolExecutor、ProcessPoolExecutor区别:
- Pool 是一个进程池,每个进程都有自己独立的内存空间,线程池是一个线程池,所有线程共享同一个内存空间。
- 相对底层,使用时需要手动调用 close() 和 join() 等方法来确保资源的正确释放。
- 各进程有独立的内存空间,能有效利用多核 CPU 的计算能力,适合处理 CPU 密集型任务。
- 进程都有独立的内存空间,创建进程时会消耗较多的内存资源。
- 进程间的数据共享较为复杂,需要借助 multiprocessing 模块提供的特定数据结构(像 Value、Array、Manager 等)来实现。
- 场景:
- 进程适合处理 CPU 密集型任务,如计算、图像处理等。
- ThreadPoolExecutor 是一个阻塞式的线程池,线程池中的线程会一直等待任务的到来,直到线程池中的线程都被占用。
- 支持 with 语句,自动关闭线程池,不需要手动调用 close() 和 join() 方法。
- 过创建多个线程达成并发。线程共享进程的内存空间,开销相对较小,适合处理 I/O 密集型任务。
- 线程共享进程的内存空间,创建线程的开销较小,内存使用相对较少。在处理大量小任务时,ThreadPoolExecutor 更为高效。
- 线程共享进程的内存空间,数据共享相对容易,可直接访问和修改共享变量,但要注意线程安全问题,可使用 threading.Lock 等同步机制来保证数据的一致性。
- 场景:
- 适合处理大量小任务,每个任务的执行时间都比较短。
- 适合处理 I/O 密集型任务,如网络请求、文件读写等。
- ProcessPoolExecutor 是一个非阻塞式的进程池,进程池中的进程会一直等待任务的到来,直到进程池中的进程都被占用。
- 基本和 ThreadPoolExecutor 使用类似。
共同点是线程池和进程池都可以用于并发执行任务,提高程序的执行效率。因为python是多线程语言,所以线程和进程执行完成的顺序是不一定的
进程
from multiprocessing import Process
import time,os
def func(name):
for _ in range(10):
print(f'{name}遍历次数:',_)
time.sleep(1)
if __name__ == '__main__':
p1=Process(target=func,args=('嬴政',))
p2=Process(target=func,args=('毛主席',))
p1.start()
p2.start()
进程间的全局变量不能共享,导致多进程之间数据在执行后数据不正确
多任务异步协程
在执行异步任务的时候,一个任务执行的时间比较长,就会导致其他任务无法执行,为了解决这个问题,就可以使用协程来解决。原理大概是:在执行一个线程的时候,进入了任务等待时间,这个时候可以执行下一个或者多个线程任务,在线程任务响应时切换到对应的线程任务继续执行剩余的程序(最形象的就是工厂或者企业为了利益最大化,三班倒模式将时间利用到极致)。这样就大大提高了CPU的执行效率,协程的效率的大大高于线程池的。
#简单用法
import asyncio,time
# 执行的是一个协程对象
async def func1():
print('我是一个异步函数1')
await asyncio.sleep(1)
print('我是异步函数1结束')
if __name__ == '__main__':
"""协程对象要执行必须借助 event_loop"""
event_loop=asyncio.get_event_loop()
event_loop.run_until_complete(func())
"""若是直接使用 asyncio.run(func()) 可能会报:
Event Loop has closed!! 因为run在finnally时候会执行 loop.close()
"""
# 执行多个协程
async def func1():
print('我是一个异步函数1')
await asyncio.sleep(1)
print('我是异步函数1结束')
return '异步函数3结果'
async def func2():
print('我是一个异步函数2')
await asyncio.sleep(2)
print('我是异步函数2结束')
return '异步函数3结果'
async def func3():
print('我是一个异步函数3')
await asyncio.sleep(3)
print('我是异步函数3结束')
return '异步函数3结果'
async def main():
start = time.time()
# Create tasks from the coroutines
task1 = asyncio.create_task(func1())
task2 = asyncio.create_task(func2())
task3 = asyncio.create_task(func3())
# Wait for all tasks to complete
# await asyncio.gather(task1, task2, task3)
# Alternatively, you could use:
done,pendding=await asyncio.wait([task1, task2, task3])
lt = list(done)
for _ in lt:
print(_.result())
"""
asyncio.wait 返回结果是无序的
result = await asyncio.gather(task1, task2, task3,return_exceptions=false)
return_exceptions=true:如果有错误信息返回错误信息,其他任务正常执行
return_exceptions=false:如果有错误信息返回错误信息,所有任务正常停止
"""
print(time.time() - start)
if __name__ == '__main__':
"""协程对象要执行必须借助 event_loop"""
# event_loop=asyncio.get_event_loop()
# event_loop.run_until_complete(task)
"""若是直接使用 asyncio.run(func()) 可能会报:
Event Loop has closed!! 因为run在finnally时候会执行 loop.close()
"""
"""3.8版本前写法
start=time.time()
f1=func1()
f2=func2()
f3=func3()
tasks=[f1,f2,f3]
asyncio.run(asyncio.wait(tasks))
print(time.time()-start)
"""
asyncio.run(main())
uvloop 是一个高性能的异步事件循环库,它是 Python 标准库 asyncio 的一个实现。uvloop 提供了比标准库 asyncio 更快的性能,特别是在处理大量并发连接时。接近于 GO 语言的协程性能。官网
进程和线程的使用
- 线程:任务相对统一,互相特别相似。
- 进程:多个任务相对独立,互相不相似没有交集。
队列
解决多进程之间数据共享问题
| 方法名称 | 描述 |
|---|---|
| qsize() | 消息数量获取当前队列包含的 |
| empty() | 判断队列是否为空为空结果为True,否则为False |
| full() | 判断队列是否满了满结果为True,否则为False |
| get(block=True) | 获取队列中的一条消息,然后从队列中移除,block默认值为True |
| get_nowait() | 相当于get(block=False),消息队列为空时,抛出异常 |
| put(item,block=True,time) | 将item消息放入队列,block默认为True time默认一直等待入列,可以设置2(即2秒后不能入队报错) |
| put_nowait(item) | 相当于put(item,block=False),在队列满时直接报错 |
# 队列
from multiprocessing import Pool, Queue, Process, Value
import time,os
def add(q, shared_a):
print(shared_a.value, f'add当前进程为{os.getpid()},父进程为{os.getppid()}')
for i in range(6):
with shared_a.get_lock():
shared_a.value += 1
q.put(shared_a.value)
print(shared_a.value, 'add 入栈的值')
def reduce(q, shared_a):
print(shared_a.value, f'reduce当前进程为{os.getpid()},父进程为{os.getppid()}')
for i in range(6):
with shared_a.get_lock():
print(shared_a.value, 'reduce')
shared_a.value -= 1
q.put(shared_a.value)
if __name__ == '__main__':
start = time.time()
# 移除队列容量限制
q = Queue()
print("*" * 20, start, "*" * 20)
# 使用 Value 实现多进程间变量共享
shared_a = Value('i', 10)
p1 = Process(target=add, args=(q, shared_a))
p2 = Process(target=reduce, args=(q, shared_a))
p1.start()
p2.start()
p1.join()
p2.join()
print(time.time() - start)
生产者消费者模型
多用于多线程或多进程中,通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不找生产者要数据,而是直接从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力。
# 生产者消费者模型
from queue import Queue
from threading import Thread
import time
#创建一个生产类
class Producer(Thread):
def __init__(self,name,queue):
Thread.__init__(self,name=name)
self.queue=queue
def run(self):
for _ in range(6):
print(f'{self.name}将产品{_}放入队列')
self.queue.put(_)
time.sleep(1)
print('生产者完成了数据的存放')
class Comsumer(Thread):
def __init__(self,name,queue):
Thread.__init__(self,name=name)
self.queue=queue
def run(self):
for _ in range(5):
value=self.queue.get()
print(f'消费者线程{self.name}取出了{value}')
time.sleep(1)
print('-'*10+'消费完成了数据的读取'+'-'*10)
if __name__ == '__main__':
q=Queue()
p=Producer('Producer',q)
c=Comsumer('Comsumer',q)
p.start()
c.start()
p.join()
c.join()
print('主程序执行完成')
Selenium
Selenium是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。
aa
pymysql
pymysql是一个用于连接MySQL数据库的Python库。它提供了一个简单易用的API,用于执行SQL查询、插入、更新和删除操作。
import pymysql
# 创建连接
conn=pymysql.connect(
user='xxxxx',
password='xxxxxxx',
host='host',
database='xxxx',
port=3306,
)
# 创建游标
cursor=conn.cursor()
metadata='{"ip": "192.168.1.1", "device": "iPhone"}'
sql='insert into comments (content, user_id, username, post_id, status)' \
f"VALUES ('这是一条评论内容商城', 1, 'john_doe', 101, 'approved');"
try:
result=cursor.execute(sql)
print('-'*30)
print(f'result',result)
print('-'*30)
conn.commit()
except e:
conn.rollback()
finally:
if cursor:
cursor.close()
conn.close()
pymongo
pymongo是一个用于连接MongoDB数据库的Python库。它提供了一个简单易用的API,用于执行MongoDB查询、插入、更新和删除操作。
from pymongo import MongoClient
def getdb ():
client=MongoClient(
host='localhost',
port=27017
)
db = client['hello']
return db
def add(db,table,data):
if isinstance(data,dict):
db[table].insert_one(data)
else:
db[table].insert_many(data)
def upd(db,table,condition,next):
db[table].update_one(condition, {"$set":next})
def delt(db,table,condition):
db[table].delete_many(condition)
if __name__ == '__main__':
db=getdb()
d={
'file':'http://localhost:8000/0240902212049.jpg',
'filename':'睁眼看世界',
'user':'湾湾',
'level':13
}
t=({
'file':'http://localhost:8000/0240902212049.jpg',
'filename':'睁眼看世界22',
'user':'湾湾',
'level':1
},{
'file': 'http://localhost:8000/0240902212049.jpg',
'filename': '睁眼看世界11',
'user': '湾湾',
'level': 11
})
# add(db,'uploadInfo',d)
# add(db,'uploadInfo',t)
n={
'file':'0240902212049.jpg',
'filename':'睁1眼看世界',
'user':'湾~湾',
'level':10
}
# upd(db,'uploadInfo',{'filename':'测试'},n)
delt(db,'uploadInfo',{'filename':None})